DBAPI‑Benutzerhandbuch
Produkteinführung
DBAPI ist ein Low‑Code‑Tool für Data‑Warehouse‑Entwickler. Durch einfaches Schreiben von SQL‑Abfragen und Konfigurieren der Parameter auf der Benutzeroberfläche werden automatisch HTTP‑Schnittstellen generiert. Es ermöglicht Entwicklern, schnell Backend‑Datenschnittstellen zu erstellen, insbesondere für BI‑Berichte und die Entwicklung von Datenvisualisierungs‑Dashboards.
DBAPI dient als zentrales Management‑System für alle Unternehmensdatenschnittstellen und stellt eine Plattform zur Verwaltung externer Datendienste dar. Es bietet Funktionen zur dynamischen Erstellung und Bereitstellung von Schnittstellen sowie deren einheitlicher Verwaltung. Zudem verfügt es über Client‑Management‑Funktionen, mit denen der Zugriff auf Schnittstellen überwacht und die entsprechenden Berechtigungen gesteuert werden können.
Kernfunktionen
- ✅ Out of the Box: Keine Programmierung erforderlich; keine Abhängigkeit von zusätzlicher Software (im Standalone‑Modus genügt lediglich eine Java‑Laufzeitumgebung).
- ✅ Leichtgewichtig: Sehr geringer Ressourcenverbrauch – ein Server mit 2 Kernen und 4 GB RAM reicht für einen stabilen Betrieb aus.
- ✅ Multiplattform‑Unterstützung: Unterstützt sowohl den Standalone‑ als auch den Cluster‑Modus; kompatibel mit Windows, Linux und macOS.
- ✅ Dynamische Konfiguration: Dynamische Erstellung und Änderung von APIs und Datenquellen; nahtloses Hot‑Deployment ohne Ausfallzeiten.
- ✅ Berechtigungsverwaltung: API‑basierte Zugriffsrechte; Unterstützung von IP‑Whitelist und -Blacklist.
- ✅ Breite Kompatibilität: Unterstützt sämtliche relationalen Datenbanken gemäß JDBC‑Spezifikation (MySQL, SQL Server, PostgreSQL, Oracle, Hive, Dameng, RenDaJinCang, Doris, OceanBase, GaussDB usw.).
- ✅ Dynamisches SQL: Unterstützt dynamisches SQL im MyBatis‑Stil; integrierte Funktionen zum Editieren, Ausführen und Debuggen von SQL‑Anweisungen.
- ✅ Umfassende Unterstützung: Unterstützt SELECT-, INSERT-, UPDATE- und DELETE‑Anweisungen sowie Aufrufe gespeicherter Prozeduren.
- ✅ Transaktionsmanagement: Mehrfache SQL‑Ausführung; flexible Steuerung der Transaktionsanwendung.
- ✅ Erweiterbare Plug‑Ins: Umfangreiche Plug‑In‑Mechanismen für Caching, Datenkonvertierung, Fehlermeldungen und Parameterverarbeitung.
- ✅ Einfache Migration: Import und Export von API‑Konfigurationen; ideal für die Migration von Test‑ zu Produktionsumgebungen.
- ✅ Parameterverarbeitung: Unterstützt Übermittlung von Parametern sowie komplexe verschachtelte JSON‑Parameter; integrierte Parametervalidierung.
- ✅ Monitoring und Statistik: Abfrage von Schnittstellenaufrufen sowie statistische Auswertungen des Zugriffs.
- ✅ Durchflusskontrolle: Unterstützung von Rate‑Limiting‑Mechanismen für APIs.
- ✅ Prozessorchestrierung: Unterstützung komplexer API‑Orchestrierungsfunktionen.
- ✅ Offene Integration: Bereitstellung einer OpenAPI‑Schnittstelle zur einfachen Anbindung an andere Systeme.
Grundlegende Konzepte
Executor
Der Executor ist eine abstrakte Darstellung der Geschäftslogik einer API. Derzeit werden verschiedene Typen unterstützt:
| Executor‑Typ | Funktionsbeschreibung |
|---|---|
| SQL‑Executor | Führt SQL‑Anweisungen in der Datenbank aus und gibt das Ergebnis zurück. |
| Elasticsearch‑Executor | Führt Elasticsearch‑DSL‑Anweisungen aus und gibt das Ergebnis zurück. |
| HTTP‑Executor | Dient als HTTP‑Client, leitet HTTP‑Anfragen weiter und gibt das Ergebnis zurück. |
[!HINWEIS] Die Personal‑Edition unterstützt derzeit nur den SQL‑Executor.
API‑Gruppe
Dient zur kategorischen Verwaltung von APIs; verwandte Business‑APIs werden in derselben Gruppe zusammengefasst, was die Wartung und Suche erleichtert.
Client
Bezeichnet die Anwendung, die die APIs der Plattform aufruft, etwa Python‑ oder Java‑Programme. Jeder Client verfügt über eine eindeutige Kennung clientId und einen Schlüssel secret, die vom Systemadministrator erstellt und mit API‑Zugriffsrechten versehen werden.
Schnellstart
Systemanmeldung
Melden Sie sich mit dem Standard‑Benutzername und Passwort admin/admin an.

Datenquellenkonfiguration
Öffnen Sie die Seite zur Datenquellenverwaltung und klicken Sie auf „Datenquelle erstellen“.
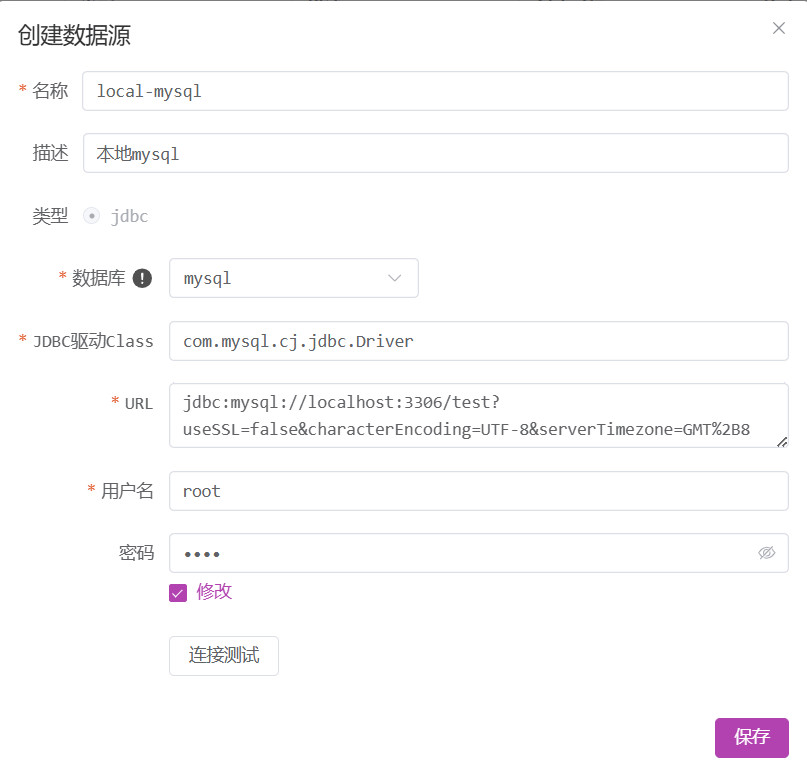
Geben Sie die Datenbankverbindungsdaten ein und speichern Sie sie.
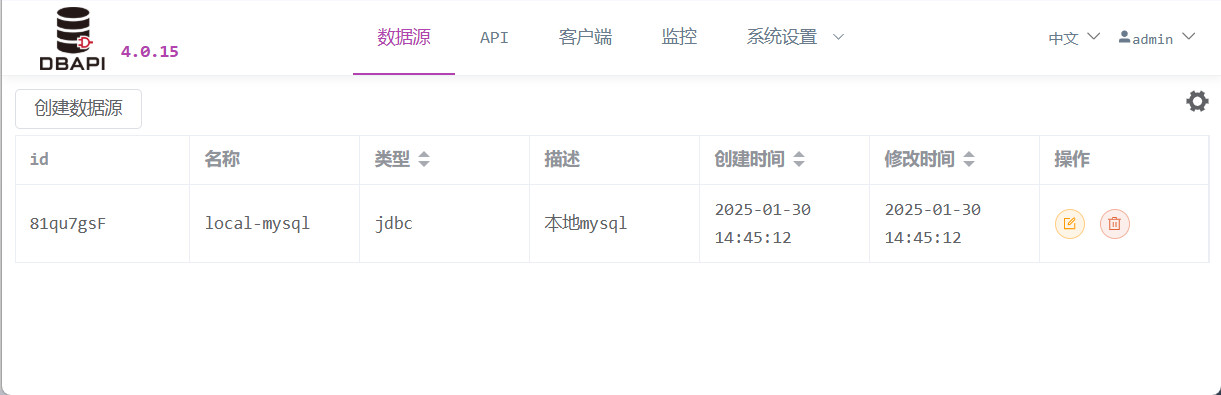
Nach dem Speichern kehren Sie zur Datenquellenliste zurück; dort können Sie die neu erstellte Datenquelle bearbeiten oder löschen.
[!WARNUNG] Wichtige Hinweise:
- Unterstützt alle Datenbanken, die JDBC‑Protokoll unterstützen.
- Bei Verwendung anderer Datenbanktypen oder Oracle müssen Sie den JDBC‑Treiberklassennamen manuell angeben und die entsprechende JDBC‑Treiber‑JAR‑Datei in das Verzeichnis
extliboderliblegen; anschließend den Dienst neu starten (im Clustermodus auf allen Knoten).- Das Verzeichnis
libenthält bereits MySQL-/SQL‑Server-/PostgreSQL-/ClickHouse‑Treiber; bei Versionsinkompatibilitäten bitte manuell austauschen.- Empfohlen wird, eigene Treiber‑JAR‑Dateien in das Verzeichnis
extlibzu legen, um eine einheitliche Verwaltung zu gewährleisten.
API‑Erstellungsprozess
1. API‑Gruppe erstellen
Öffnen Sie die API‑Verwaltungsseite und klicken Sie links auf „API‑Gruppe erstellen“.
Geben Sie im Pop‑Up‑Fenster den Namen der Gruppe ein und speichern Sie.
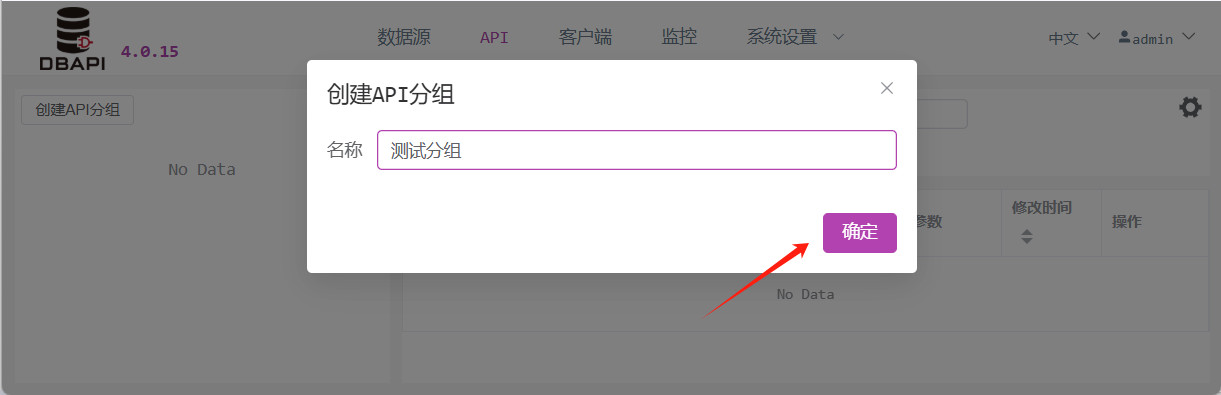
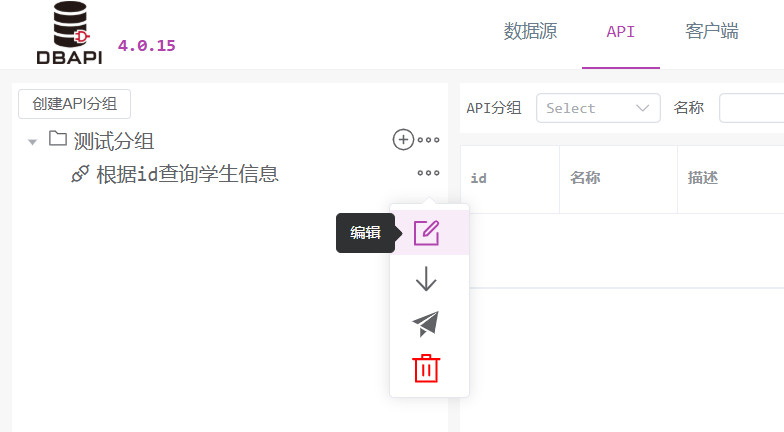
Nach dem Speichern erscheint links eine neue Gruppe; klicken Sie auf das „Mehr“‑Symbol neben der Gruppe, um sie zu bearbeiten oder zu löschen.
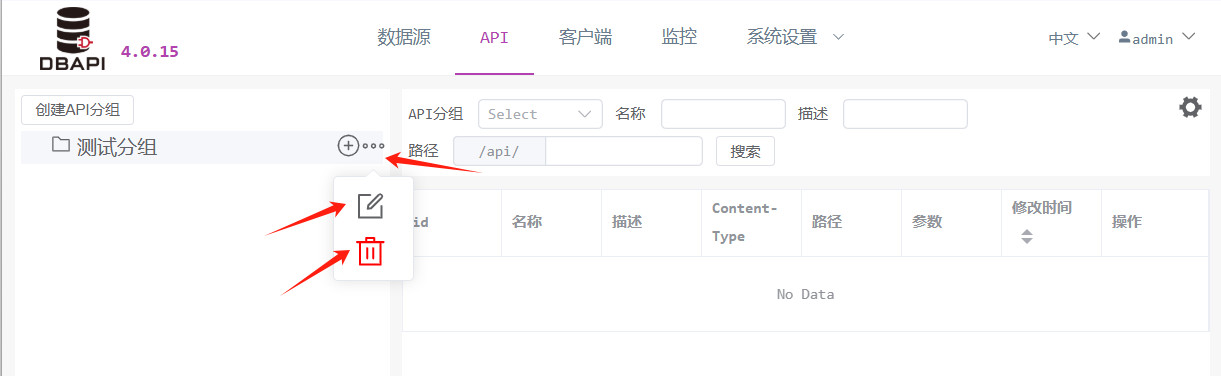
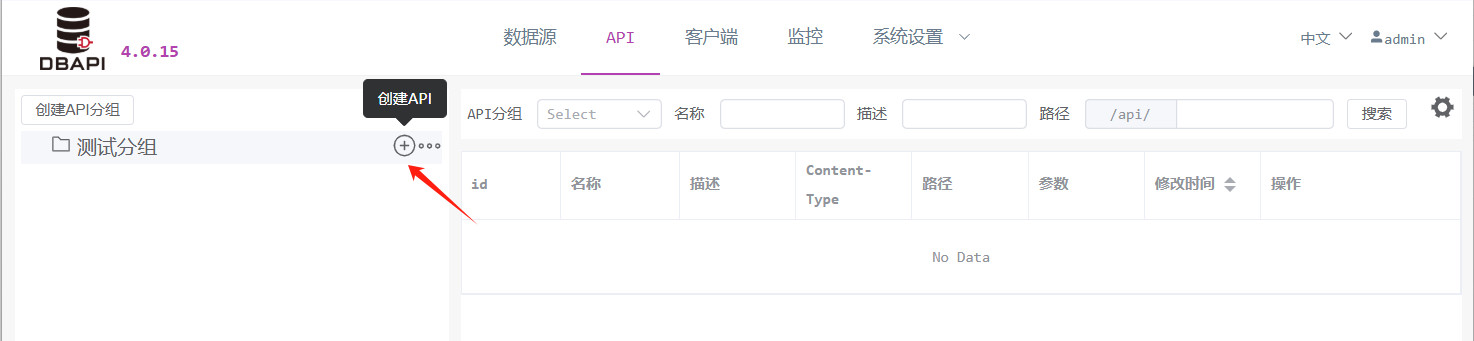
2. API erstellen
Klicken Sie in der Zielgruppe auf die Schaltfläche „API erstellen“, um zur Konfigurationsseite zu gelangen.
Klicken Sie auf „Grundlegende Informationen“ und geben Sie die Basisinformationen der API ein.
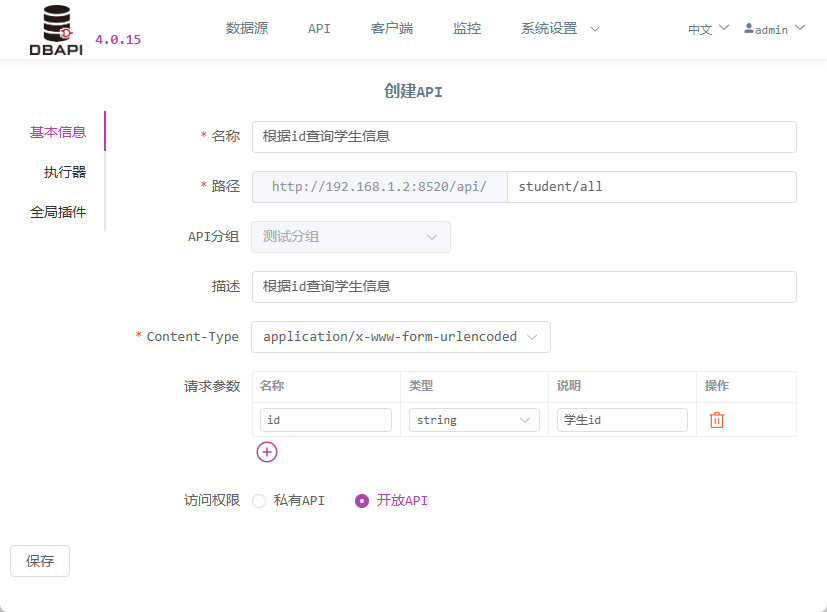
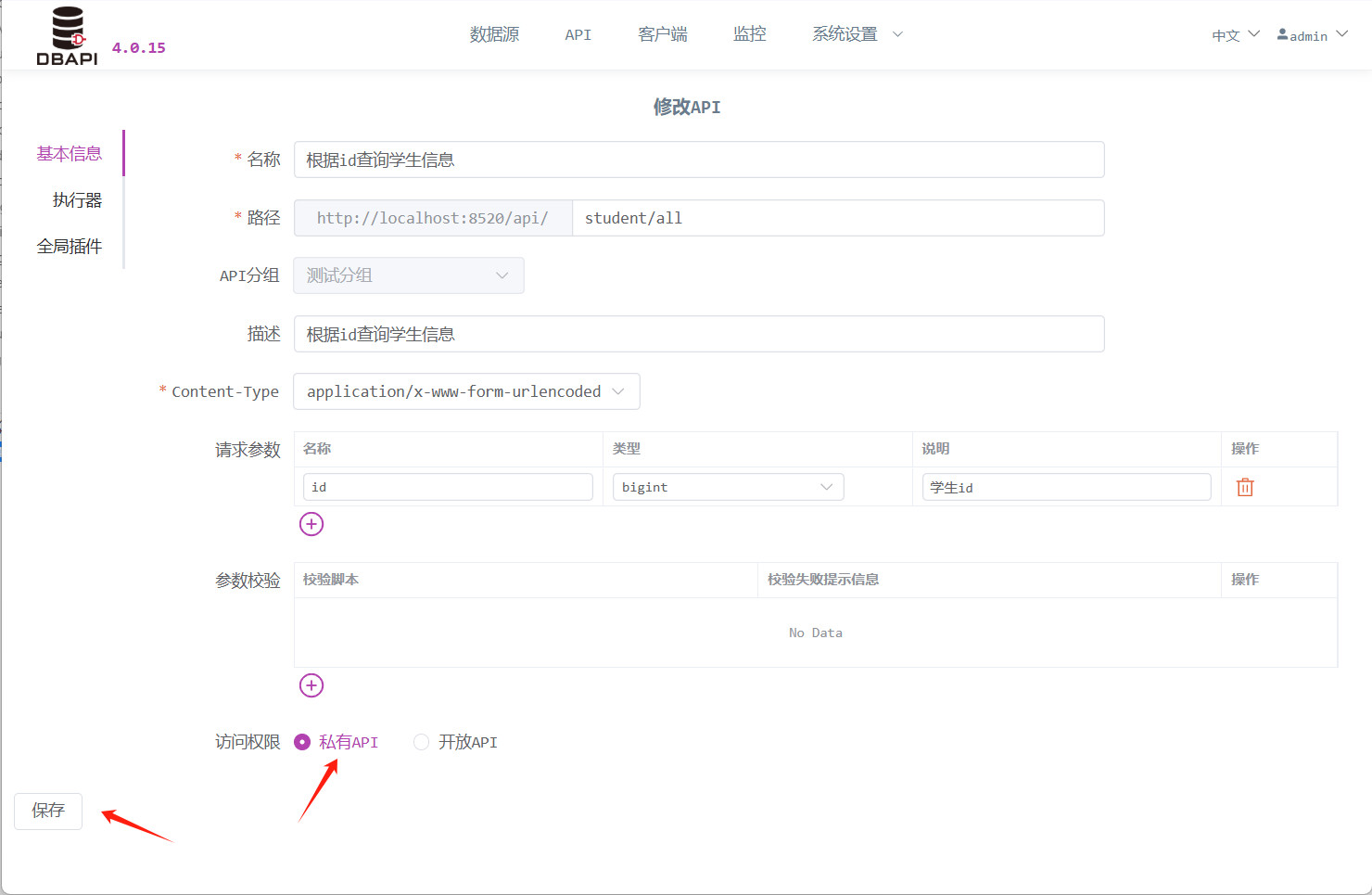
Zugriffsrecht: Offene Schnittstellen sind direkt zugänglich; private Schnittstellen erfordern von Clients die Beantragung eines Tokens (hier wählen wir zunächst eine offene Schnittstelle, um später testen zu können).
Pfad: Kann beliebig mehrstufig konfiguriert werden, z. B.
/a/b/c,/a/b/c/d.Content-Type: Für APIs vom Typ
application/x-www-form-urlencodedmüssen Parameter konfiguriert werden; für APIs vom Typapplication/jsonist ein JSON‑Parameterbeispiel anzugeben.Klicken Sie auf „Executor“ und füllen Sie die Executor‑Informationen aus.
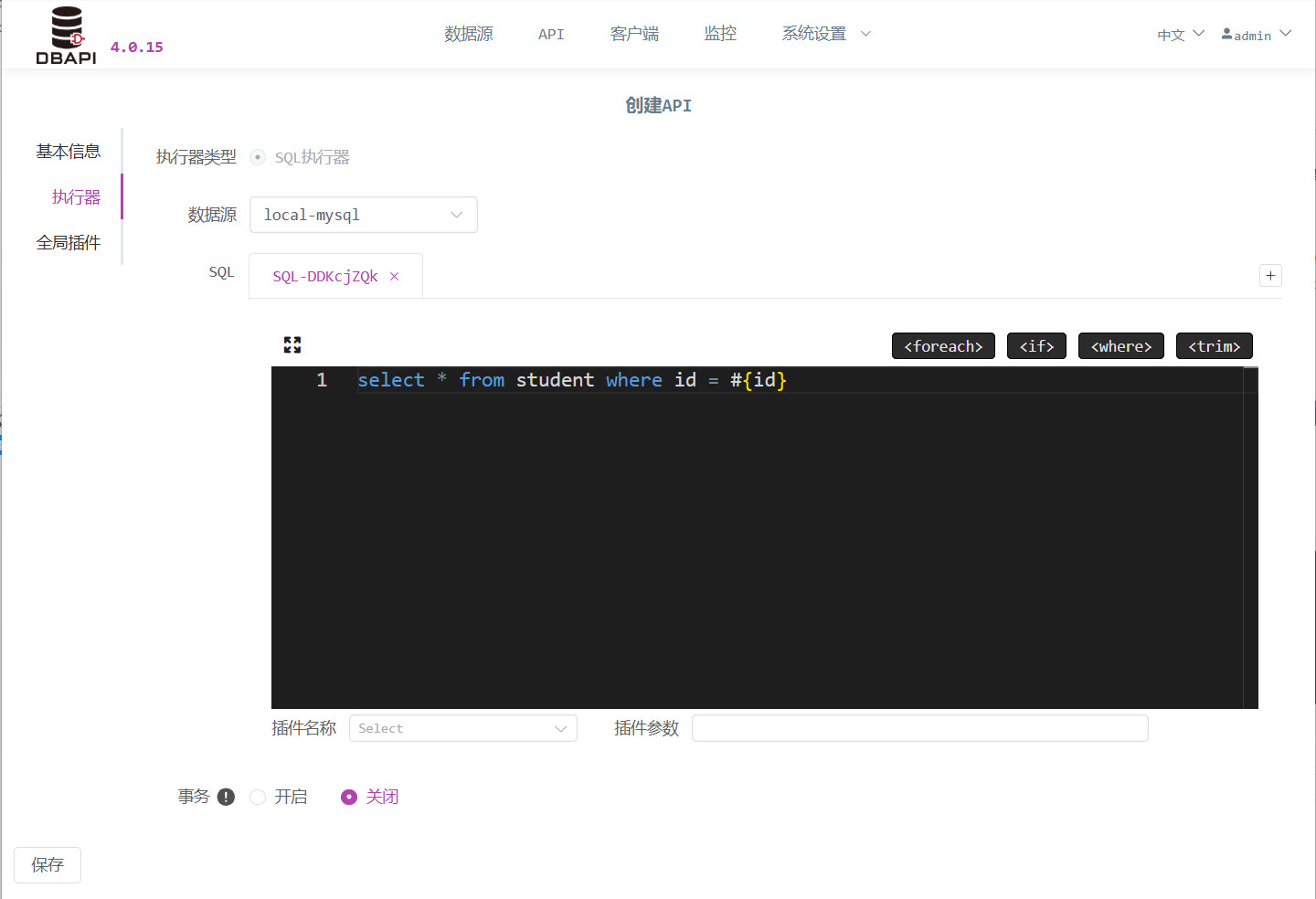
SQL‑Schreiben: Verwendet die dynamische SQL‑Syntax von MyBatis (ohne äußere
<select>‑,<insert>‑,<delete>‑ oder<update>‑Tags); Parameter werden mit#{}oder${}markiert. Weitere Details zur dynamischen SQL‑Syntax finden Sie in der Dokumentation dynamische SQL‑Syntax.Transaktionssteuerung: Standardmäßig ist die Transaktion deaktiviert; bei INSERT-/UPDATE-/DELETE‑Anweisungen empfiehlt sich die Aktivierung, da bei einem fehlgeschlagenen SQL‑Ausdruck die Transaktion rückgängig gemacht wird. Wenn innerhalb einer API mehrere SQL‑Anweisungen ausgeführt werden sollen, sollten diese in einer einzigen Transaktion zusammengefasst werden.
Wichtiges Hinweis: Bei Datenbanken wie HIVE, die keine Transaktionen unterstützen, bitte die Transaktion nicht aktivieren; sonst kommt es zu Fehlern.
Datenkonvertierung: Falls eine Datenkonvertierung erforderlich ist, geben Sie den Java‑Klassennamen des entsprechenden Plug‑Ins an; bleibt dieses Feld leer, erfolgt keine Konvertierung. Sollte das Plug‑In Parameter benötigen, geben Sie diese ebenfalls an. Weitere Details entnehmen Sie bitte der Plug‑In‑Dokumentation.
Unterstützung mehrerer SQL‑Anweisungen: Klicken Sie auf die Schaltfläche „Hinzufügen“, um ein weiteres SQL‑Schreibfenster zu öffnen; innerhalb einer API können mehrere SQL‑Anweisungen ausgeführt werden, deren Ergebnisse schließlich zusammengefasst und zurückgegeben werden – beispielsweise bei Paginierungsabfragen, wenn sowohl Detail‑ als auch Gesamtzahl‑Informationen abgerufen werden sollen. In einem einzelnen SQL‑Schreibfenster darf jedoch nur eine einzige Anweisung geschrieben werden.
[!TIPP] Enthält ein Executor mehrere SQL‑Anweisungen, so wird jeder einzelne SQL‑Ausdruck mit einer eigenen Datenkonvertierungs‑Plug‑In‑Konfiguration versehen; das Plug‑In konzentriert sich stets auf das Ergebnis einer einzelnen SQL‑Anweisung.
Klicken Sie auf die Schaltfläche „Fenster maximieren“, um zur SQL‑Debugging‑Oberfläche zu gelangen.
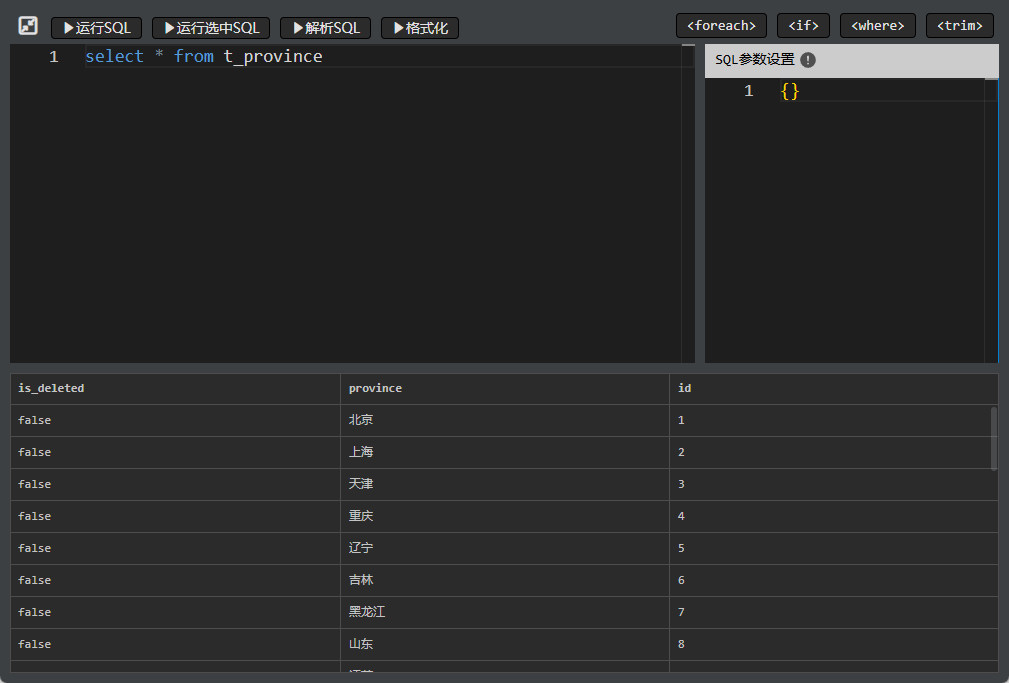
Klicken Sie auf „SQL ausführen“, um die Anweisung zu testen; falls das SQL Parameter enthält, müssen diese vorher festgelegt werden.
Klicken Sie auf „Globales Plug‑In“, um die globalen Plug‑In‑Informationen einzugeben.
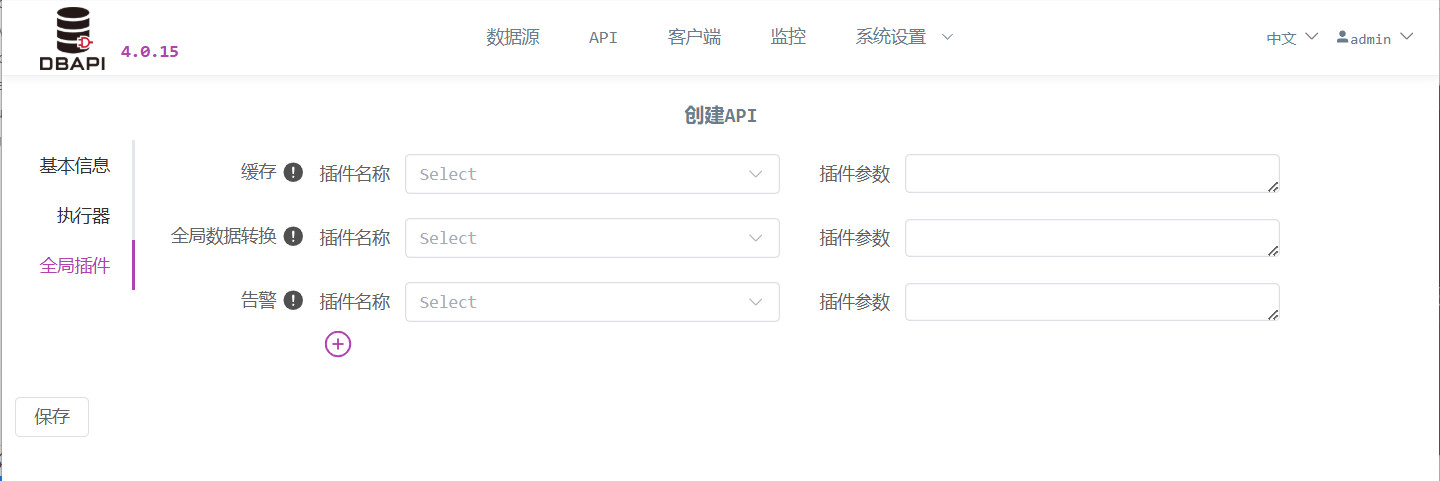
Cache: Falls ein Datencache erforderlich ist, geben Sie den Java‑Klassennamen des Cache‑Plug‑Ins an; bleibt dieses Feld leer, wird kein Cache aktiviert. Sollte das Plug‑In Parameter benötigen, geben Sie diese ebenfalls an.
Alarm: Falls bei einem fehlgeschlagenen API‑Aufruf ein Alarm ausgelöst werden soll, geben Sie den Java‑Klassennamen des Alarm‑Plug‑Ins an; bleibt dieses Feld leer, wird kein Alarm ausgelöst. Sollte das Plug‑In Parameter benötigen, geben Sie diese ebenfalls an.
Globale Datenkonvertierung: Falls eine Datenkonvertierung erforderlich ist, geben Sie den Java‑Klassennamen des entsprechenden Plug‑Ins an; bleibt dieses Feld leer, erfolgt keine Konvertierung. Sollte das Plug‑In Parameter benötigen, geben Sie diese ebenfalls an.
Parameterverarbeitung: Falls eine Parameterverarbeitung nötig ist, geben Sie den Java‑Klassennamen des entsprechenden Plug‑Ins an; bleibt dieses Feld leer, erfolgt keine Verarbeitung. Sollte das Plug‑In Parameter benötigen, geben Sie diese ebenfalls an.
Weitere Details entnehmen Sie bitte der Plug‑In‑Dokumentation.
Klicken Sie auf „Speichern“, um die API zu erstellen; über das API‑Menü gelangen Sie wieder zur API‑Liste.
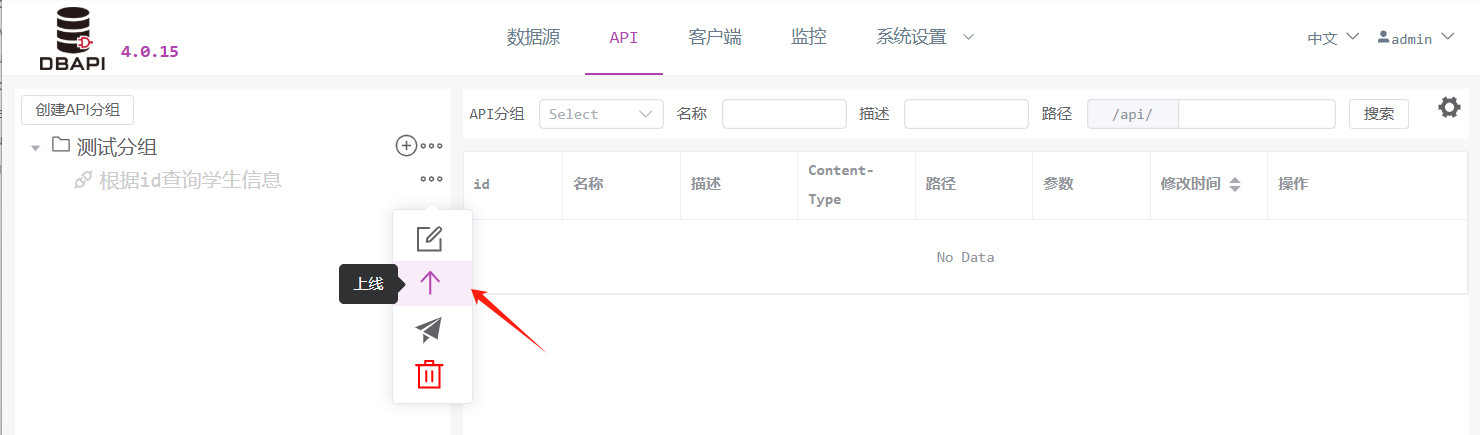
3. API veröffentlichen
Klicken Sie auf das „Mehr“‑Symbol neben der API; dort erscheint die Schaltfläche „Online stellen“. Klicken Sie darauf, um die API zu veröffentlichen.
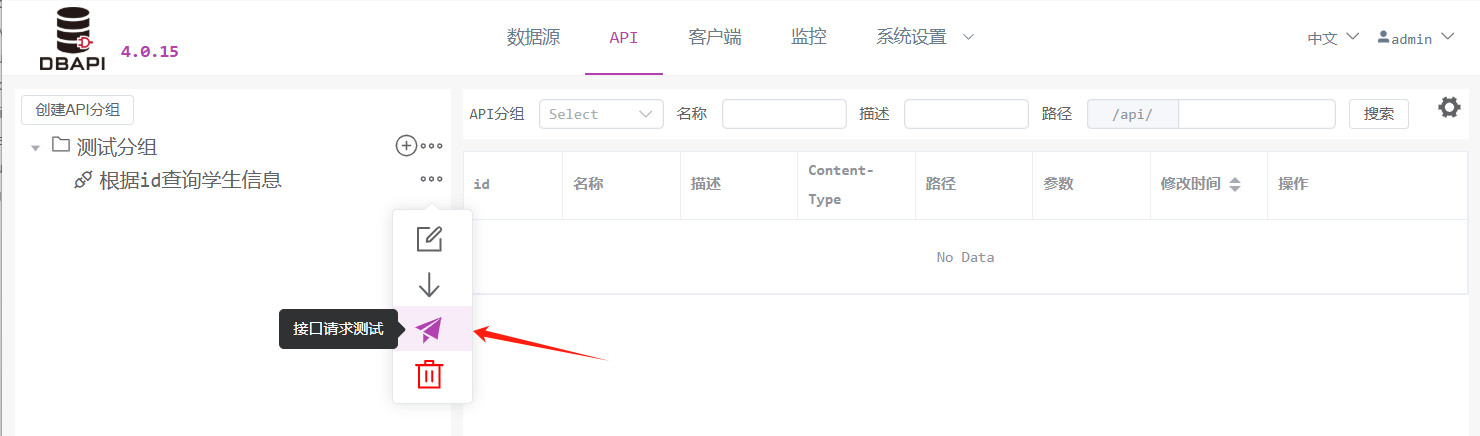
Klicken Sie auf das „Mehr“‑Symbol neben der API; dort erscheint die Schaltfläche „Request‑Test“. Klicken Sie darauf, um zur Request‑Test‑Seite zu gelangen.
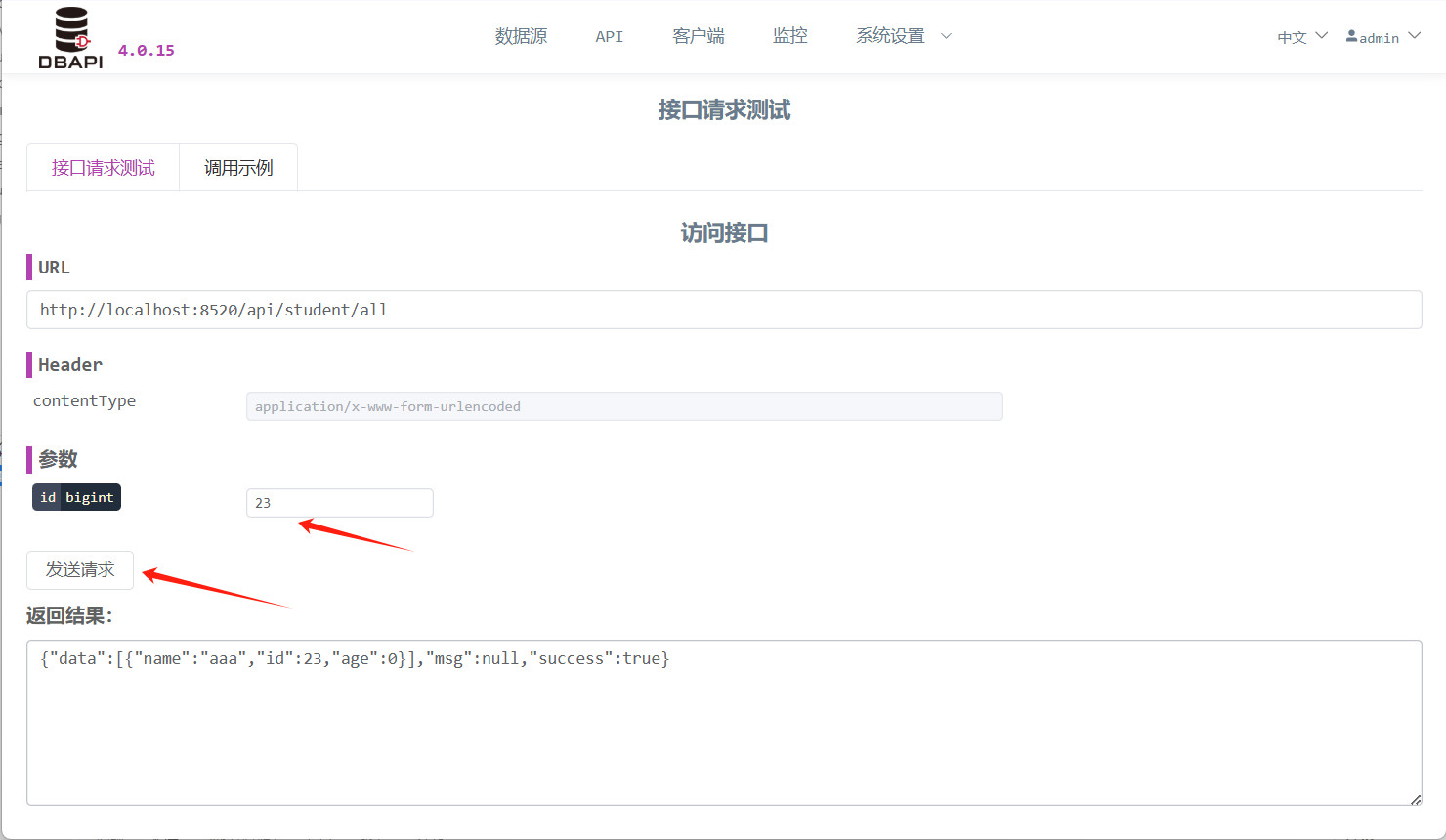
Klicken Sie auf die Schaltfläche „Anfrage senden“, um eine Anfrage zu stellen; falls Parameter vorhanden sind, müssen diese vorher eingegeben werden.
Client‑Verwaltung
Klicken Sie auf das Client‑Menü und dann auf die Schaltfläche „Client erstellen“.
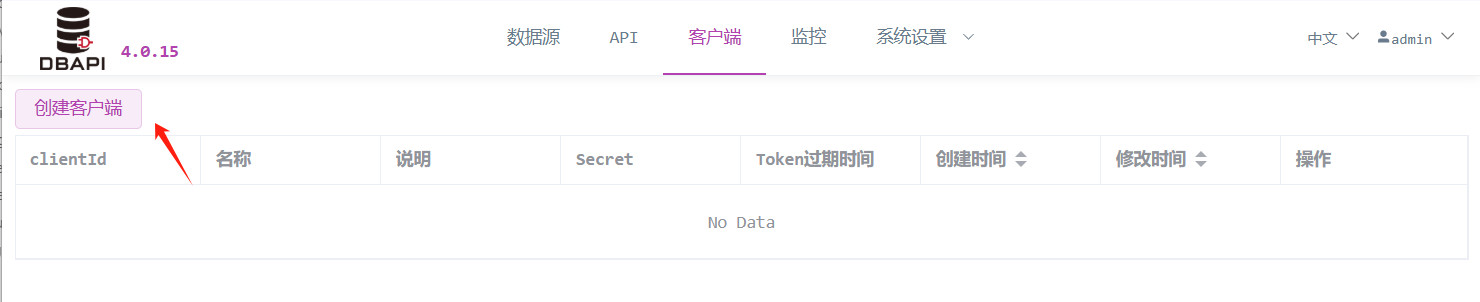
Geben Sie die Client‑Informationen ein und speichern Sie.
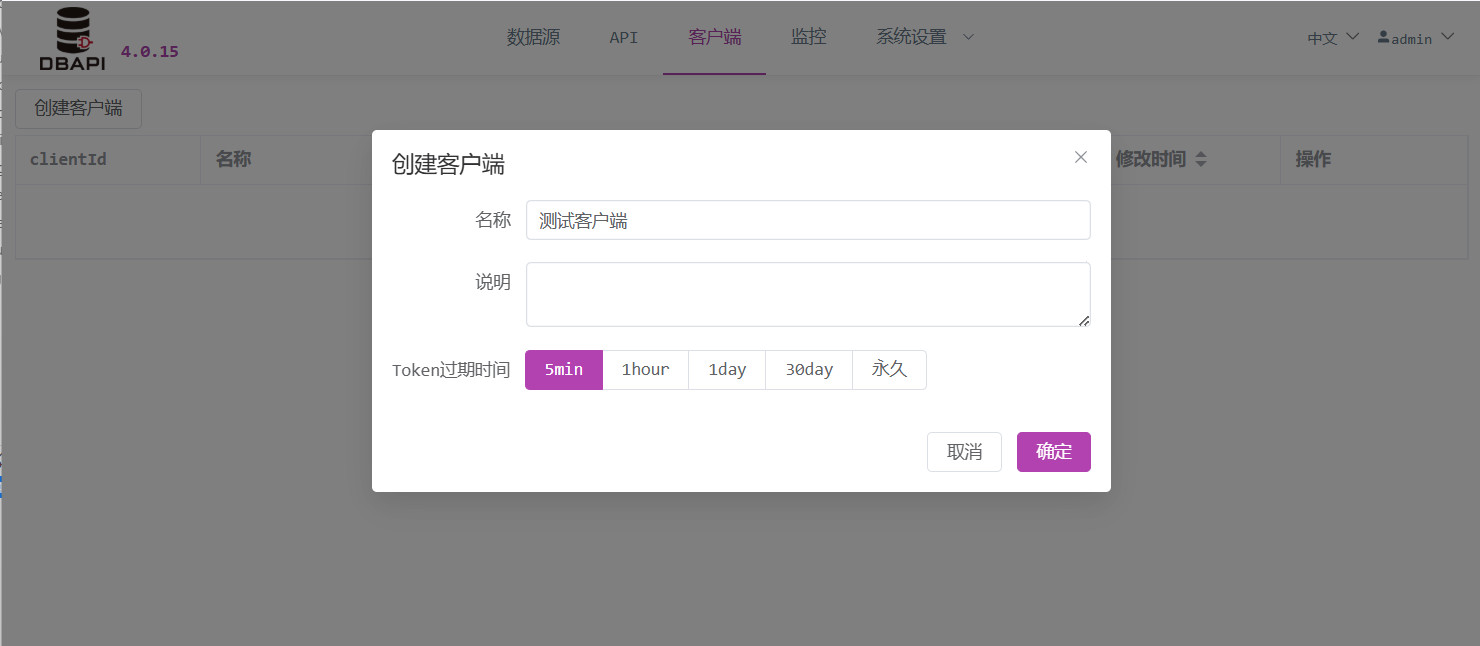
Bei der Erstellung eines Clients werden eine clientId und ein secret generiert; der Systemadministrator muss diese beiden Werte dem Client (dem API‑Aufrufer) bekanntgeben.
Der Client verwendet seine eigene clientId und sein eigenes secret, um die Adresse http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxx aufzurufen und dynamisch ein Token zu erhalten. Nur mit diesem Token kann der Client auf private APIs zugreifen – vorausgesetzt, der Systemadministrator hat diesem Client bereits die entsprechenden Zugriffsrechte für diese privaten APIs erteilt.
Bei der Erstellung eines Clients muss eine Token‑Ablaufzeit festgelegt werden; jedes Mal, wenn der Client ein neues Token beantragt, erhält er ein entsprechendes Ablaufdatum. Solange das Token gültig ist, bleibt der Zugriff auf die API mit dem zuletzt beantragten Token gültig; nach Ablauf dieser Frist muss ein neues Token beantragt werden.
[!TIPP] Wenn Sie möchten, dass das Token unbegrenzt gültig bleibt, setzen Sie die Ablaufzeit auf einen sehr hohen Wert, etwa 100 Jahre.
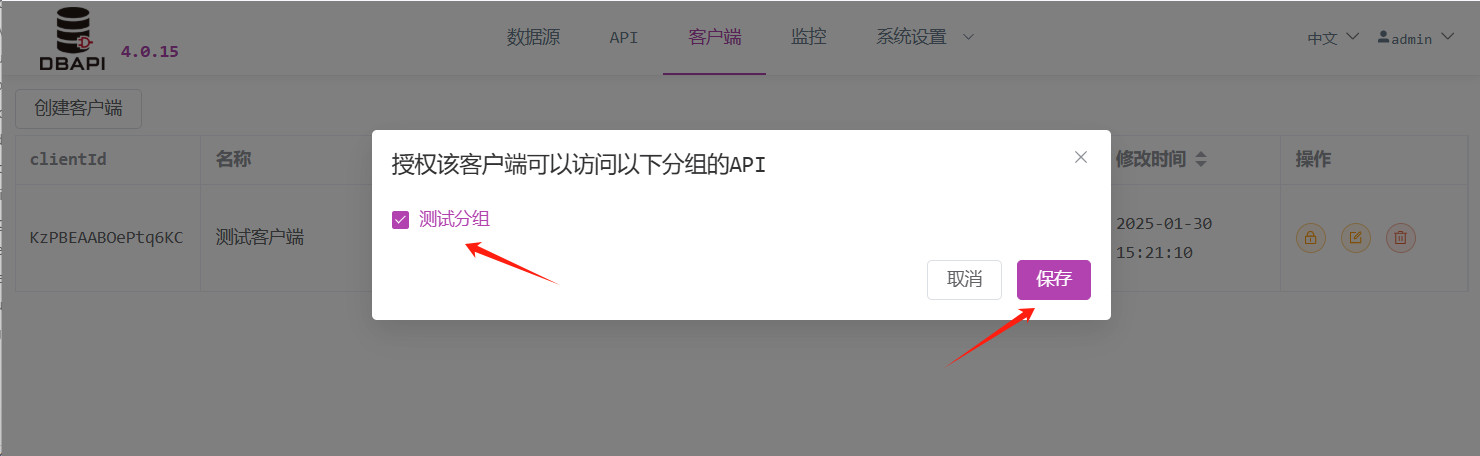
Klicken Sie auf die Schaltfläche „Autorisierung“, um dem Client die entsprechenden APIs zu autorisieren.
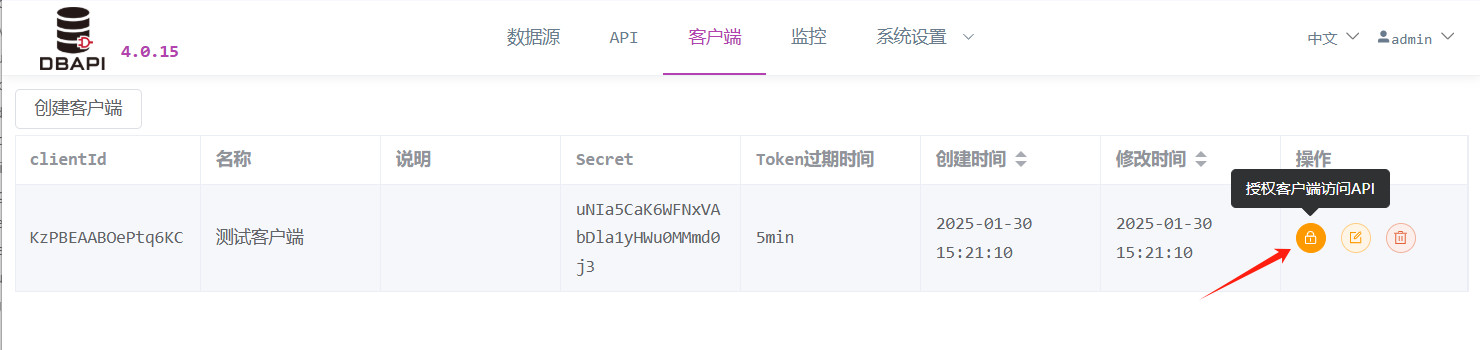
Wählen Sie die zu autorisierenden Gruppen aus und speichern Sie.
Token‑Nutzungshinweise
Token‑Beantragungsschnittstelle:
http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxxBeim Aufruf privater APIs muss der Token‑Wert im Header‑Feld „Authorization“ eingetragen werden; nur so ist ein erfolgreicher Zugriff möglich. (Für offene APIs ist kein Header erforderlich.)
Python‑Aufrufbeispiel:
import requests
headers = {"Authorization": "5ad0dcb4eb03d3b0b7e4b82ae0ba433f"}
re = requests.post("http://127.0.0.1:8520/api/userById", {"idList": [1, 2]}, headers=headers)
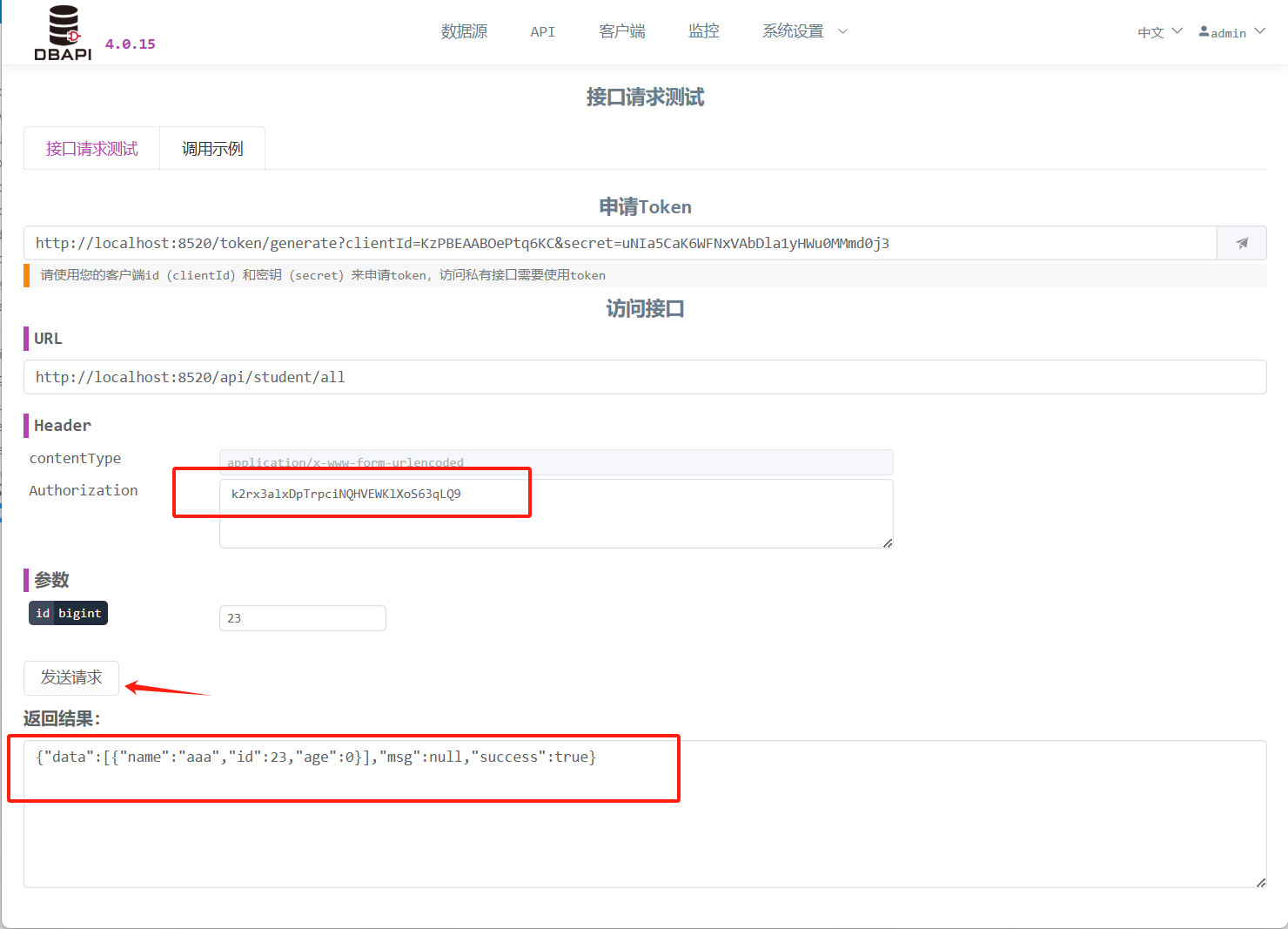
print(re.text)Ändern Sie die zuvor erstellte API in eine private Schnittstelle und klicken Sie anschließend erneut auf die Schaltfläche „Request‑Test“.
Klicken Sie nun auf die Schaltfläche „Anfrage senden“; bemerken Sie, dass die API nicht zugänglich ist.
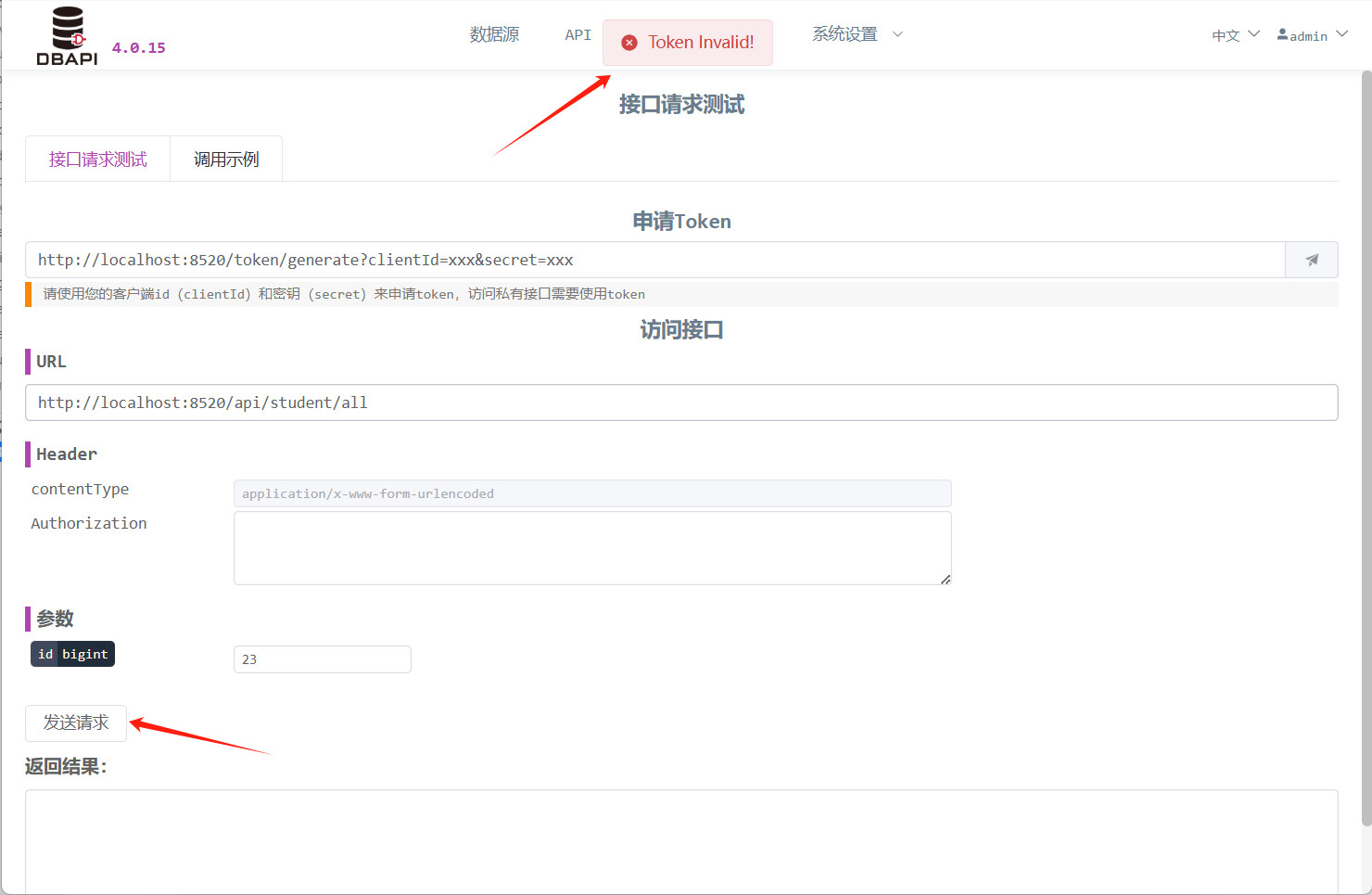
Geben Sie Ihre
clientIdund Ihrsecretein und klicken Sie auf die Schaltfläche, um das Token zu erhalten.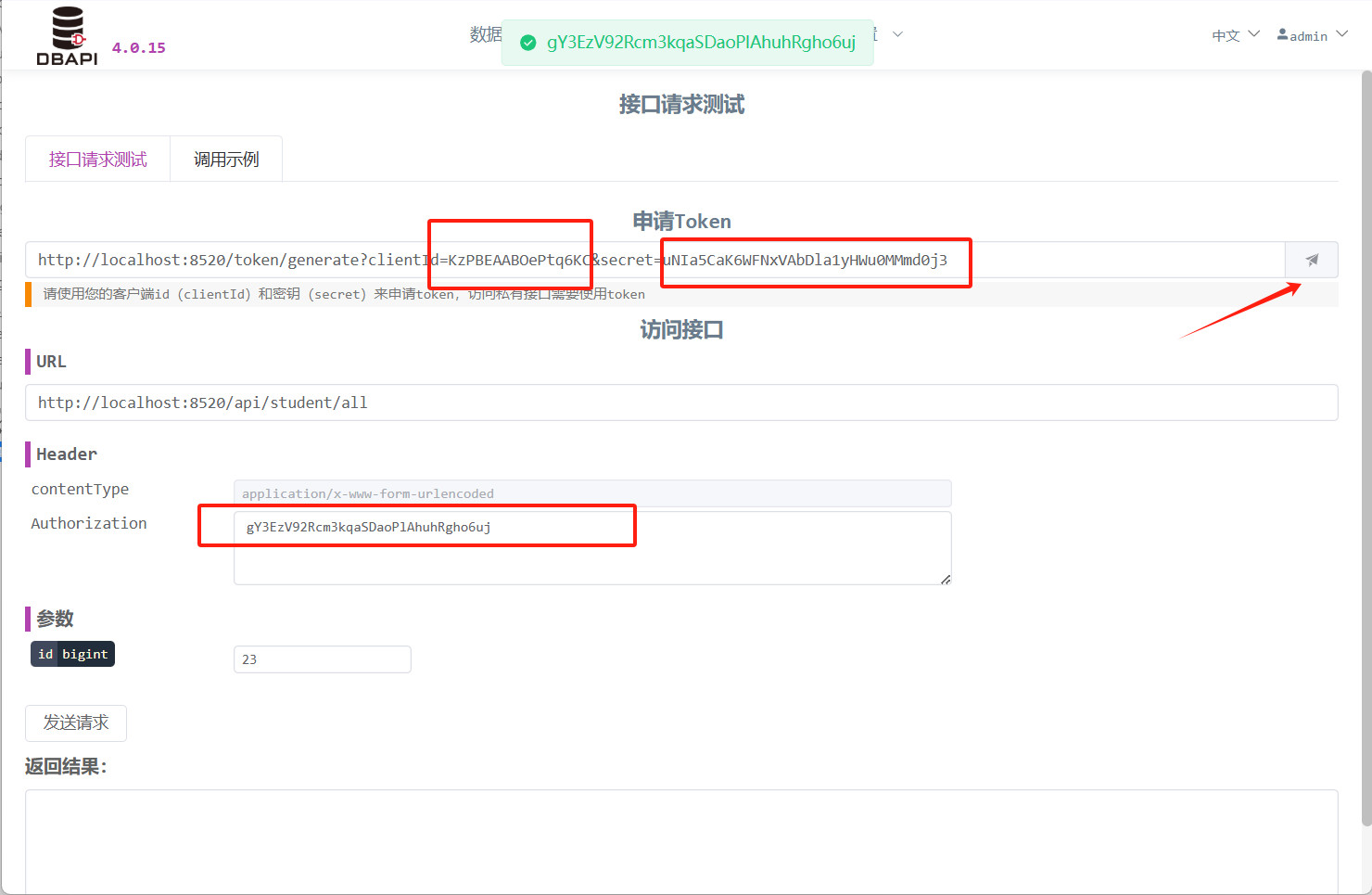
Tragen Sie das Token in das Header‑Feld „Authorization“ ein und klicken Sie erneut auf die Schaltfläche „Anfrage senden“; bemerken Sie, dass die API nun erfolgreich zugänglich ist.
IP‑Firewall‑Einstellungen
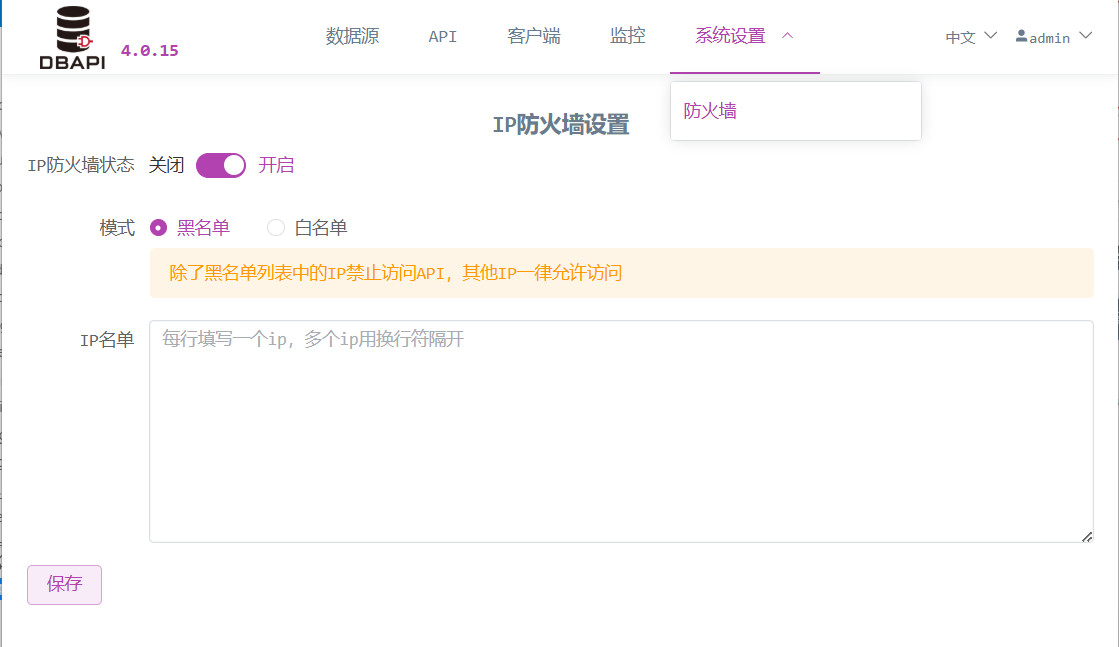
Durch das Aktivieren der Firewall können bestimmte IP‑Adressen blockiert werden.
Monitoring
DBAPI kann bereits ohne weitere Abhängigkeiten ausschließlich mit einer Metadatenbank (PostgreSQL, MySQL oder SQLite) verwendet werden. Wenn Sie jedoch die auf der Seite verfügbaren Überwachungsfunktionen nutzen möchten – etwa zur Erfassung von API-Aufrufprotokollen, Zugriffszahlen, Erfolgsquoten und ähnlichen Metriken –, ist zusätzlich eine separate Protokolldatenbank erforderlich, die vom Benutzer selbst eingerichtet werden muss, um die API‑Zugriffsprotokolle zu speichern. Empfohlen werden ClickHouse, MySQL, PostgreSQL oder Doris; natürlich können auch andere relationale Datenbanken verwendet werden.
Derzeit stehen Initialisierungsskripte für ClickHouse, MySQL und PostgreSQL in dem Verzeichnis sql bereit.
[!HINWEIS] Wenn Sie die Überwachungsfunktionen nicht benötigen, können Sie auf den Aufbau einer Protokolldatenbank verzichten und in der Datei
conf/application.propertiesden Eintragaccess.log.writer=nullkonfigurieren. (Die Standardkonfiguration lautet bereitsaccess.log.writer=null.)
Protokollerfassungsverfahren
Dateibasierte Erfassung: DBAPI schreibt die API‑Zugriffsprotokolle standardmäßig in die Datei
logs/dbapi-access.log. Nutzer können diese Protokolle anschließend mithilfe von Tools wieDataXoderFlumein eine Protokolldatenbank übertragen.Direkter Datenbankzugriff: Wird in der Datei
conf/application.propertiesder Eintragaccess.log.writer=dbkonfiguriert, schreibt DBAPI die API‑Zugriffsprotokolle asynchron direkt in die Protokolldatenbank. Dieses Verfahren eignet sich besonders für Szenarien mit relativ geringem Protokollvolumen.Kafka‑Pufferung: Ist in der Datei
conf/application.propertiesder Eintragaccess.log.writer=kafkafestgelegt, schreibt DBAPI die API‑Zugriffsprotokolle in Kafka. Die nachfolgende Weiterleitung der Protokolle in eine Protokolldatenbank erfolgt dann durch den Nutzer selbst; dieses Verfahren empfiehlt sich bei hohem Protokollvolumen, da Kafka als Puffer dient.
[!HINWEIS] Beachten Sie, dass in diesem Fall in der Datei
conf/application.propertiesdie Kafka‑Adressen angegeben werden müssen.Darüber hinaus verfügt DBAPI über ein eigenes Tool, das Kafka‑Protokolle liest und in die Protokolldatenbank überträgt. Verwenden Sie hierzu das Skript
bin/dbapi-log-kafka2db.sh.
Überwachung und Zusammenfassung
Über das Menü „Überwachung“ können Sie die Protokolle der API‑Aufrufe einsehen.
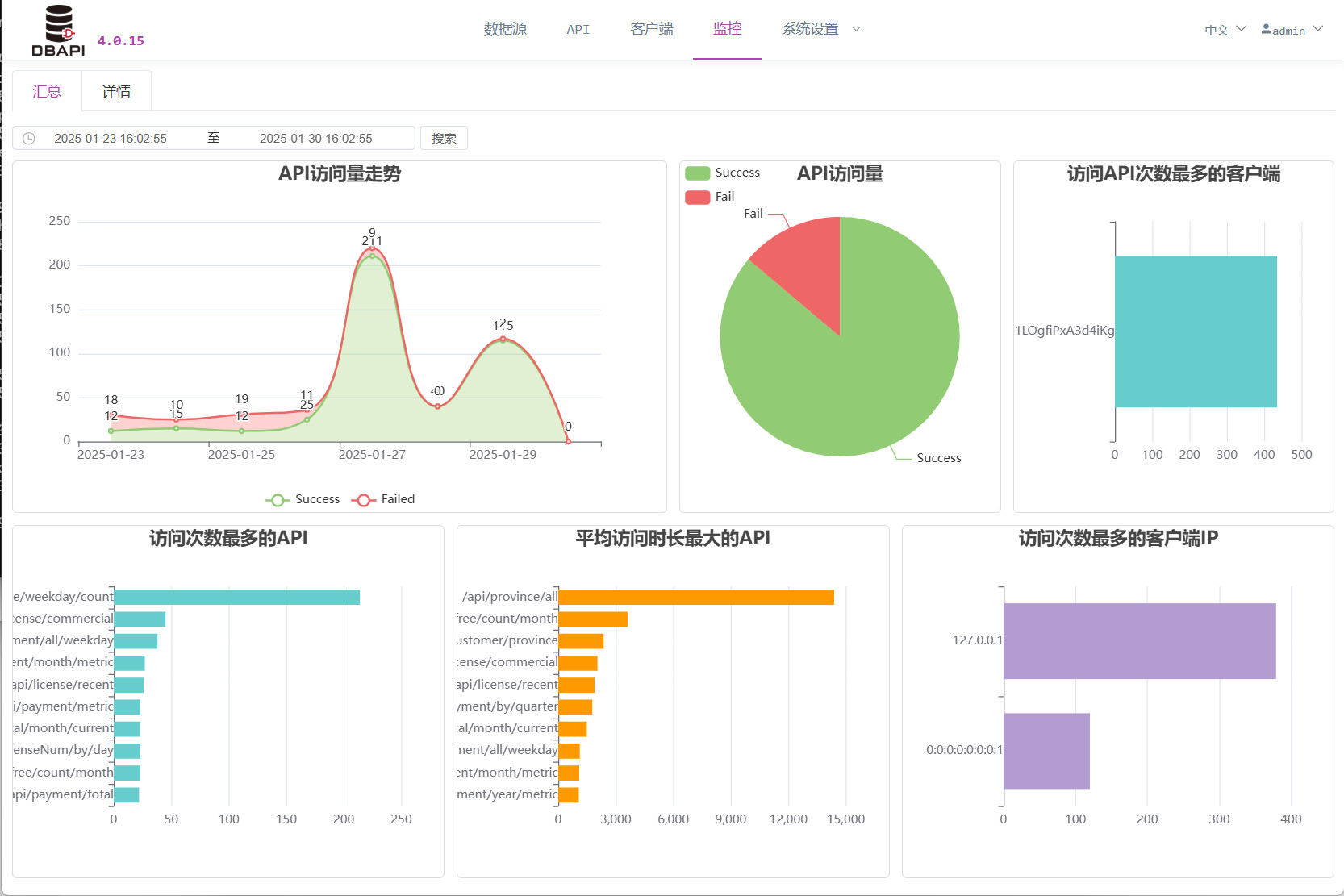
Klicken Sie auf die Registerkarte „Details“, um nach API‑Aufrufen zu suchen.

Weitere Funktionen
Exportieren der Schnittstellen‑Dokumentation
Klicken Sie im API‑Menü auf die Schaltfläche „Tools“ und anschließend auf „Exportieren der Schnittstellen‑Dokumentation“.
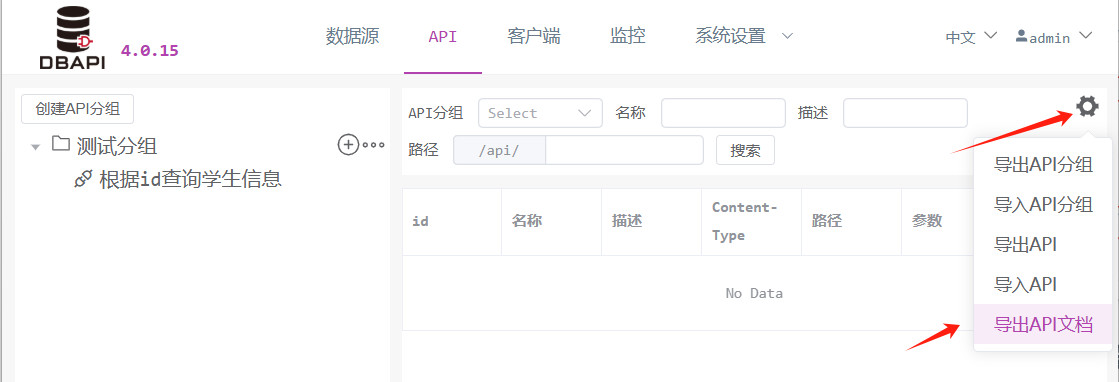
Plugin‑System
DBAPI bietet fünf Arten von Plugins an. Sie können Plugins im Plugin‑Markt herunterladen. Falls Sie eigene Plugins entwickeln möchten, beachten Sie bitte die Plugin‑Dokumentation.
Cache‑Plugin
- Es ermöglicht das Caching der Ergebnisse von Ausführern: Beispielsweise werden bei SQL‑Executoren abfragende SQL‑Anweisungen und deren Ergebnisse zwischengespeichert, wodurch häufige Datenbankabfragen und damit verbundene Belastungen reduziert werden.
- Die Caching‑Logik wird vom Benutzer selbst implementiert; es können verschiedene Speicherlösungen wie Ehcache, Redis oder MongoDB genutzt werden.
- Wird kein passendes Ergebnis im Cache gefunden, wird der Ausführer ausgeführt und das Ergebnis anschließend im Cache gespeichert.
[!TIPP] Mehrere SQL‑Anweisungen im SQL‑Executor Bei einem SQL‑Executor, der mehrere SQL‑Anweisungen enthält, kapselt das Cache‑Plugin die Ergebnisse aller Anweisungen – sofern für einzelne Anweisungen Konvertierungs‑Plugins konfiguriert sind – und speichert das Gesamtergebnis.
Alarm‑Plugin
- Wenn innerhalb einer API ein Fehler auftritt, kann das Alarm‑Plugin entsprechende Warnmeldungen versenden – etwa per E‑Mail, SMS, DingTalk, Feishu oder Enterprise WeChat.
- Die Alarmlogik wird vom Benutzer selbst definiert.
Datenkonvertierungs‑Plugin
- Manchmal liefert SQL nicht sofort das gewünschte Datenformat; in solchen Fällen bietet sich die Nutzung eines Datenkonvertierungs‑Plugins an, um die Daten mittels benutzerdefinierter Logik weiterzubearbeiten.
- Beispielsweise können Telefonnummern oder Bankkontonummern im SQL‑Ergebnis anonymisiert werden.
[!TIPP] Mehrere SQL‑Anweisungen im SQL‑Executor Bei einem SQL‑Executor, der mehrere SQL‑Anweisungen enthält, wird jedes einzelne SQL‑Ergebnis separat mit einem eigenen Datenkonvertierungs‑Plugin verarbeitet.
Globales Datenkonvertierungs‑Plugin
- Standardmäßig werden API‑Antworten im Format
{success: true, msg: xxx, data: xxx}zurückgegeben. - In bestimmten Fällen ist eine Umwandlung des Antwortformats erforderlich; beispielsweise verlangt das Low‑Code‑Frontend‑Framework AMIS, dass alle API‑Antworten das Feld
statusenthalten. Hier kommt das globale Datenkonvertierungs‑Plugin zum Einsatz, das das gesamte API‑Ergebnis entsprechend umwandelt.
[!ANMERKUNG] Unterschied zwischen Datenkonvertierungs‑ und globalem Datenkonvertierungs‑Plugin Das Datenkonvertierungs‑Plugin wandelt die Ergebnisse eines Ausführers um – etwa die Ergebnisse einer SQL‑Abfrage –, während das globale Datenkonvertierungs‑Plugin das gesamte API‑Ergebnis formatiert.
Parameterverarbeitungs‑Plugin
- Es ermöglicht die benutzerdefinierte Bearbeitung von Anforderungsparametern:
- Beispielsweise kann der Wert aller Anforderungsparameter in Großbuchstaben umgewandelt werden.
- Oder die API empfängt verschlüsselte Parameter, die vom Benutzer mittels eigener Logik entschlüsselt werden.
[!ANMERKUNG] Versionshinweis Das Parameterverarbeitungs‑Plugin wird ab Version 4.0.16 in der Personal‑Edition sowie ab Version 4.1.10 in der Enterprise‑Edition unterstützt.
Hinweise
Unterstützung für Datenquellen
- Wenn Sie Oracle oder andere Datenquellen verwenden möchten, müssen Sie die entsprechenden JDBC‑Treiber manuell in das Verzeichnis
extliboderlibder DBAPI‑Installation kopieren. Bei Cluster‑Installationen ist dies auf jedem Knoten erforderlich. - Wir empfehlen die Platzierung im Verzeichnis
extlib, um eine zentrale Verwaltung zu erleichtern.
SQL‑Schreibstandards
- Ähnlich wie bei MyBatis Dynamic SQL unterstützt DBAPI die Parameternotationen
#{}und${}. Weitere Details finden Sie in der Dokumentation zu Dynamic SQL. Es ist nicht notwendig, die äußeren Tags wie<select>oder<update>zu verwenden; schreiben Sie einfach den SQL‑Inhalt. - Achten Sie darauf, dass wie bei MyBatis das Zeichen „<“ in SQL nicht als einfaches „<“ geschrieben wird, sondern als
<.