Guía de uso de DBAPI
Introducción al producto
DBAPI es una herramienta de bajo código dirigida a desarrolladores de almacenes de datos. Solo es necesario escribir SQL en la interfaz y configurar los parámetros para generar automáticamente interfaces HTTP. Ayuda a los programadores a desarrollar rápidamente interfaces de datos del lado del servidor, especialmente adecuada para el desarrollo de interfaces backend de informes BI y pantallas grandes de visualización de datos.
DBAPI es el centro de gestión de todas las interfaces de datos de la empresa, así como la plataforma de administración para ofrecer servicios de datos al exterior. Proporciona funciones de creación y publicación dinámica de interfaces de datos, gestión unificada de dichas interfaces y capacidades de administración de clientes, permitiendo monitorear las llamadas a las interfaces desde los clientes y controlar sus permisos de acceso.
Características principales
- ✅ Listo para usar: No requiere programación ni dependencia de otros software (en modo standalone solo se necesita el entorno de ejecución de Java).
- ✅ Despliegue ligero: Ocupa muy pocos recursos; un servidor con 2 núcleos y 4 GB de RAM puede ejecutarlo de manera estable.
- ✅ Soporte multiplataforma: Admite modos standalone y en clúster, así como Windows, Linux y macOS.
- ✅ Configuración dinámica: Permite crear y modificar APIs y fuentes de datos en tiempo real, con despliegue en caliente sin interrupciones.
- ✅ Control de permisos: Ofrece gestión de permisos de acceso a nivel de API y admite listas blancas y negras de IP.
- ✅ Compatibilidad amplia: Soporta todas las bases de datos relacionales que implementan el protocolo JDBC (MySQL, SQL Server, PostgreSQL, Oracle, Hive, Dameng, Kingbase, Doris, OceanBase, GaussDB, etc.).
- ✅ SQL dinámico: Compatible con SQL dinámico al estilo MyBatis, con funcionalidades integradas de edición, ejecución y depuración de consultas.
- ✅ Soporte completo: Admite sentencias Select, Insert, Update y Delete, así como la invocación de procedimientos almacenados.
- ✅ Gestión transaccional: Permite ejecutar múltiples instrucciones SQL y controlar de forma flexible el inicio y finalización de transacciones.
- ✅ Extensiones mediante plugins: Ofrece una rica variedad de plugins para caché, transformación de datos, alertas ante fallos y procesamiento de parámetros.
- ✅ Migración sencilla: Permite importar y exportar configuraciones de API, facilitando la migración entre entornos de prueba y producción.
- ✅ Procesamiento de parámetros: Soporta pasaje de parámetros en las interfaces y envío de JSON anidado complejo, además de funciones de validación de parámetros.
- ✅ Monitoreo y estadísticas: Proporciona funciones de consulta de registros de llamadas a las interfaces y de recopilación de estadísticas de acceso.
- ✅ Control de tráfico: Admite mecanismos de limitación de tasa para las APIs.
- ✅ Orquestación de flujos: Soporta funciones avanzadas de orquestación de APIs complejas.
- ✅ Integración abierta: Ofrece una interfaz OpenAPI para facilitar la integración con otros sistemas.
Conceptos básicos
Ejecutor
El ejecutor es una abstracción que representa la lógica de negocio de las APIs. Actualmente admite varios tipos:
| Tipo de ejecutor | Descripción |
|---|---|
| Ejecutor SQL | Ejecuta sentencias SQL en la base de datos y devuelve los resultados. |
| Ejecutor Elasticsearch | Ejecuta consultas DSL de Elasticsearch y devuelve los resultados. |
| Ejecutor HTTP | Actúa como cliente HTTP, reenvía solicitudes HTTP y retorna los resultados. |
[!NOTA] En la versión personal solo está disponible el ejecutor SQL.
Grupo de APIs
Se utiliza para organizar y gestionar las APIs por categorías, agrupando aquellas relacionadas con un mismo negocio para facilitar su mantenimiento y búsqueda.
Cliente
Se refiere a las aplicaciones que llaman a las APIs de la plataforma, como aplicaciones escritas en Python o Java. Cada cliente posee un identificador único clientId y una clave secreta secret, creados y asignados por el administrador del sistema para otorgar permisos de acceso a las APIs.
Primeros pasos
Inicio de sesión en el sistema
Utilice las credenciales predeterminadas admin/admin para iniciar sesión.

Configuración de la fuente de datos
Acceda a la página de gestión de fuentes de datos y haga clic en "Crear fuente de datos".
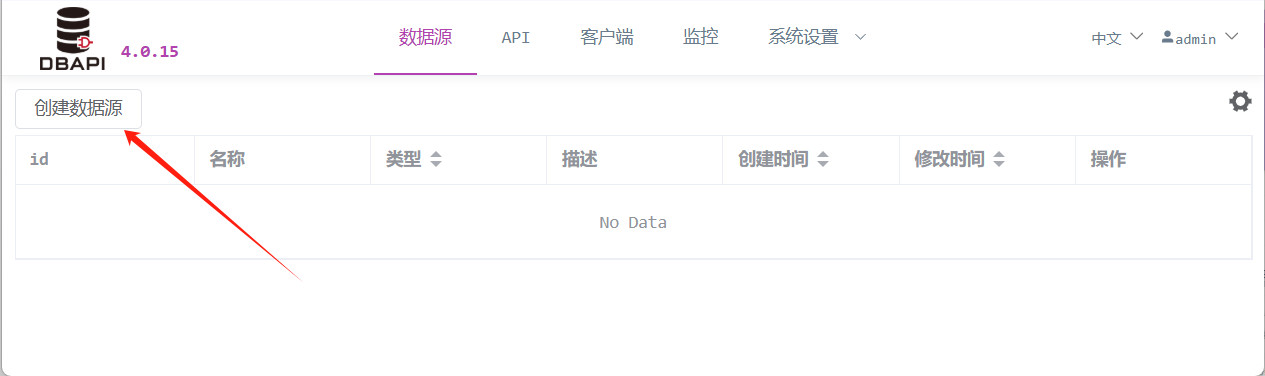
Complete la información de conexión a la base de datos y guarde los cambios.
Tras guardar, regrese a la página de fuentes de datos, donde podrá editar o eliminar la fuente recién creada.
[!ADVERTENCIA] Nota importante:
- Se admiten todas las bases de datos que soportan el protocolo JDBC.
- Si utiliza otro tipo de base de datos o Oracle, deberá especificar manualmente la clase del driver JDBC y colocar el archivo JAR correspondiente en el directorio
extlibolib, luego reiniciar el servicio (en modo clúster, esta operación debe realizarse en todos los nodos).- El directorio
libya incluye los drivers para MySQL, SQL Server, PostgreSQL y ClickHouse; si la versión no coincide, reemplace manualmente.- Se recomienda colocar los propios archivos JAR de los drivers en el directorio
extlibpara una gestión unificada.
Proceso de creación de una API
1. Creación de un grupo de APIs
Acceda a la página de gestión de APIs y haga clic en el botón "Crear grupo de APIs" en el panel izquierdo.
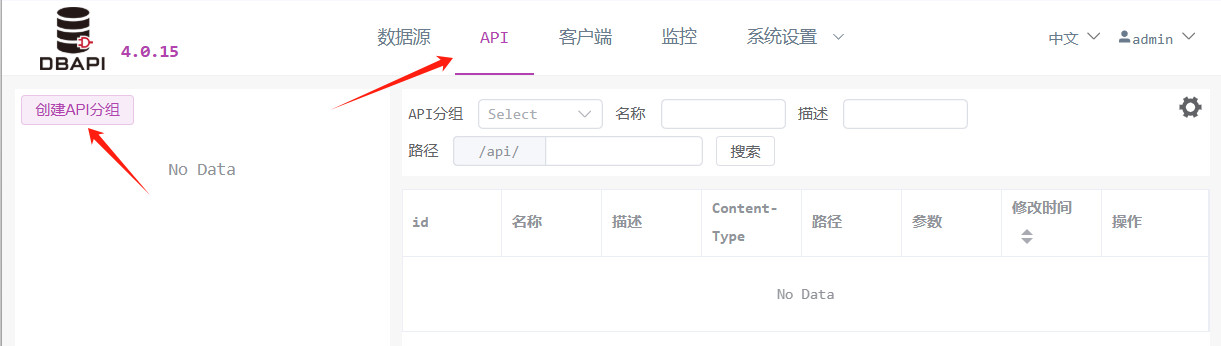
En la ventana emergente, ingrese el nombre del grupo y guárdelo.
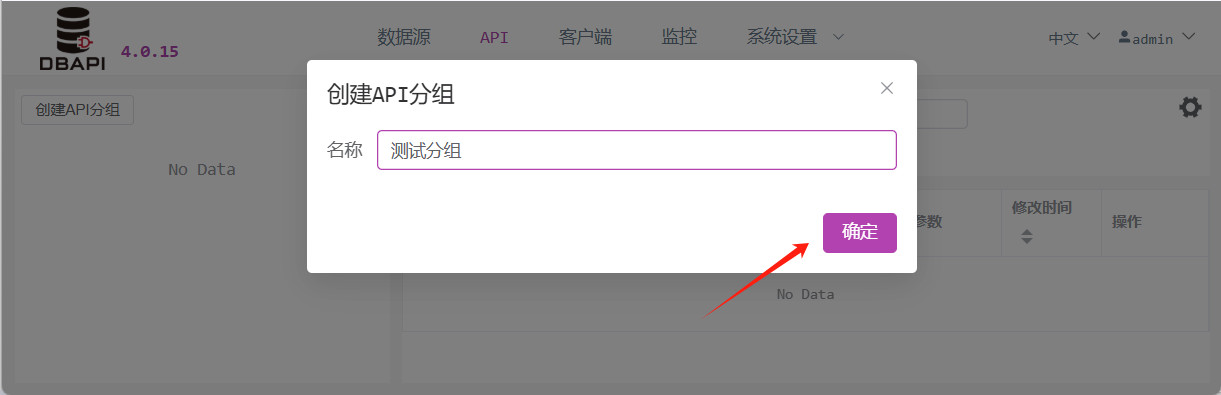
Tras guardar, verá el nuevo grupo añadido en el panel izquierdo; haga clic en el botón "Más" junto al grupo para editar o eliminarlo.
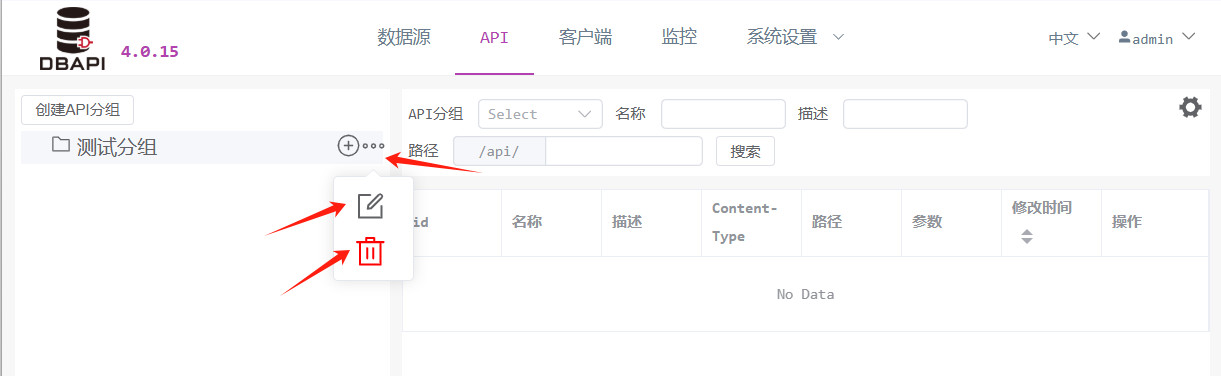
2. Creación de una API
En el grupo deseado, haga clic en el botón "Crear API" para acceder a la página de configuración.
Haga clic en la sección de Información básica para completar los datos fundamentales de la API.
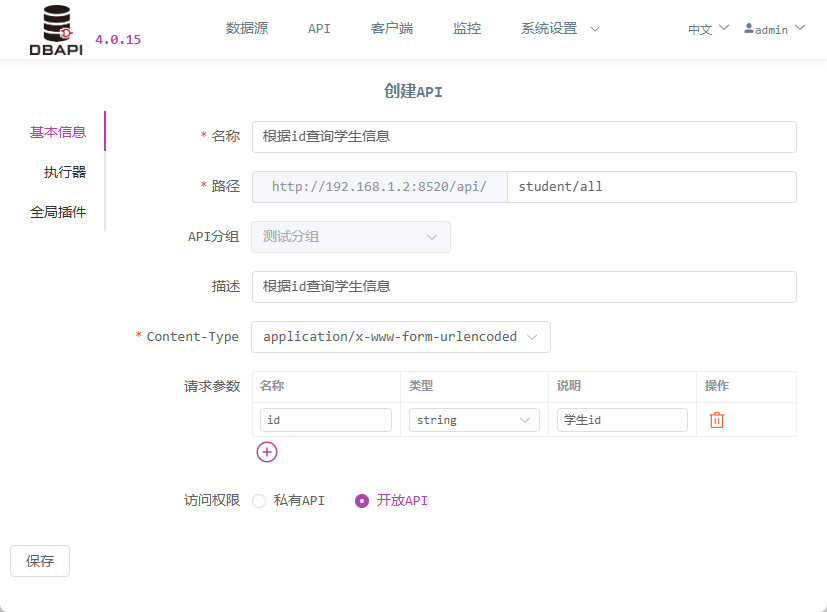
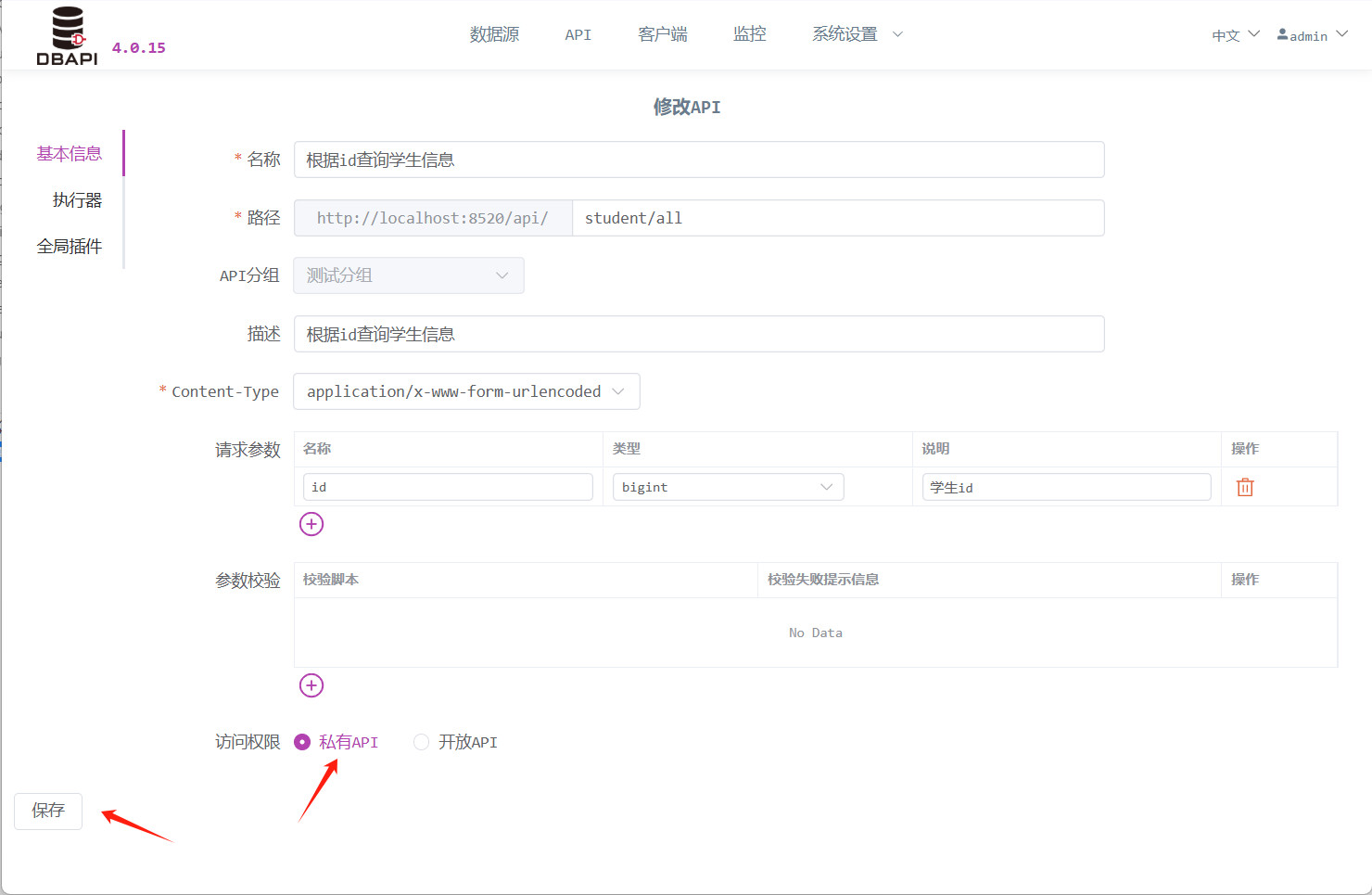
Permisos de acceso: Las APIs públicas pueden ser accesibles directamente, mientras que las privadas requieren que los clientes soliciten un token para poder acceder (aquí seleccionaremos inicialmente una API pública para facilitar las pruebas posteriores).
Ruta: Puede configurarse con cualquier número de niveles, por ejemplo:
/a/b/c,/a/b/c/d.Content-Type: Si la API utiliza el formato
application/x-www-form-urlencoded, será necesario configurar los parámetros; si esapplication/json, deberá proporcionarse un ejemplo de parámetro JSON.Haga clic en la sección de Ejecutor para completar la información correspondiente.
Escribir SQL: Utilice la sintaxis dinámica de SQL de MyBatis (sin necesidad de etiquetas externas
<select>,<insert>,<delete>o<update>). Los parámetros se indican con#{}o${}, y la sintaxis específica de SQL dinámico puede consultarse en el documento sobre SQL dinámico.Control transaccional: Por defecto, las transacciones están desactivadas. Para sentencias
insert,updateodelete, se recomienda activarlas; así, si alguna instrucción falla, la transacción se revertirá. Si dentro de una misma API hay varias instrucciones SQL, activar la transacción hará que todas se ejecuten dentro de un mismo bloque.Nota importante: Si utiliza bases de datos como Hive que no admiten transacciones, no active esta opción; de lo contrario, se producirá un error.
Transformación de datos: Si es necesario realizar alguna transformación de datos, indique el nombre de la clase Java del plugin correspondiente; si no se indica, no habrá transformación. Si el plugin requiere parámetros, especifique también estos. Consulte el documento sobre plugins para más detalles.
Soporte para múltiples instrucciones SQL: Haga clic en el botón "Agregar" para añadir una nueva ventana de escritura SQL. Una sola API puede ejecutar varias instrucciones SQL, y los resultados finales se empaquetan y devuelven juntos; por ejemplo, en consultas paginadas, una misma interfaz puede obtener tanto los detalles como el total de registros. En cada ventana de escritura SQL solo se permite una única instrucción.
[!CONSEJO] Si un mismo ejecutor contiene varias instrucciones SQL, cada una tendrá su propia configuración de plugin de transformación de datos; estos plugins siempre actúan sobre los resultados de una única instrucción SQL.
Haga clic en el botón de maximizar la ventana para acceder a la interfaz de depuración SQL.
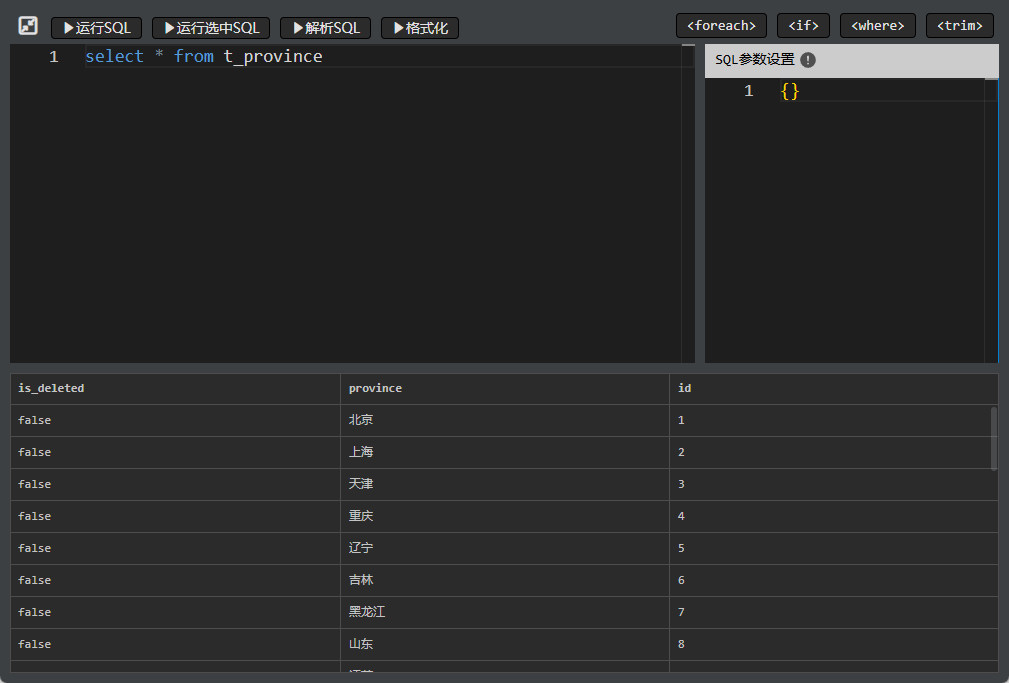
Haga clic en "Ejecutar SQL" para probar la consulta; si la instrucción contiene parámetros, asegúrese de configurarlos correctamente.
Haga clic en la sección de Plugins globales para completar la información correspondiente.
Caché: Si desea habilitar la caché de datos, indique el nombre de la clase Java del plugin correspondiente; si no se indica, la caché permanecerá desactivada. Si el plugin requiere parámetros, especifique también estos.
Alertas: Si desea recibir notificaciones en caso de fallos durante la ejecución de la API, indique el nombre de la clase Java del plugin de alertas; si no se indica, no se activará ninguna alerta. Si el plugin requiere parámetros, incluya también estos.
Transformación global de datos: Si es necesario realizar alguna transformación de datos, indique el nombre de la clase Java del plugin correspondiente; si no se indica, no habrá transformación. Si el plugin requiere parámetros, especifique también estos.
Procesamiento de parámetros: Si desea procesar los parámetros, indique el nombre de la clase Java del plugin correspondiente; si no se indica, no habrá procesamiento. Si el plugin requiere parámetros, incluya también estos.
Consulte el documento sobre plugins para obtener detalles específicos.
Haga clic en "Guardar" para crear la API; luego, acceda al menú de APIs para volver a la lista de APIs.
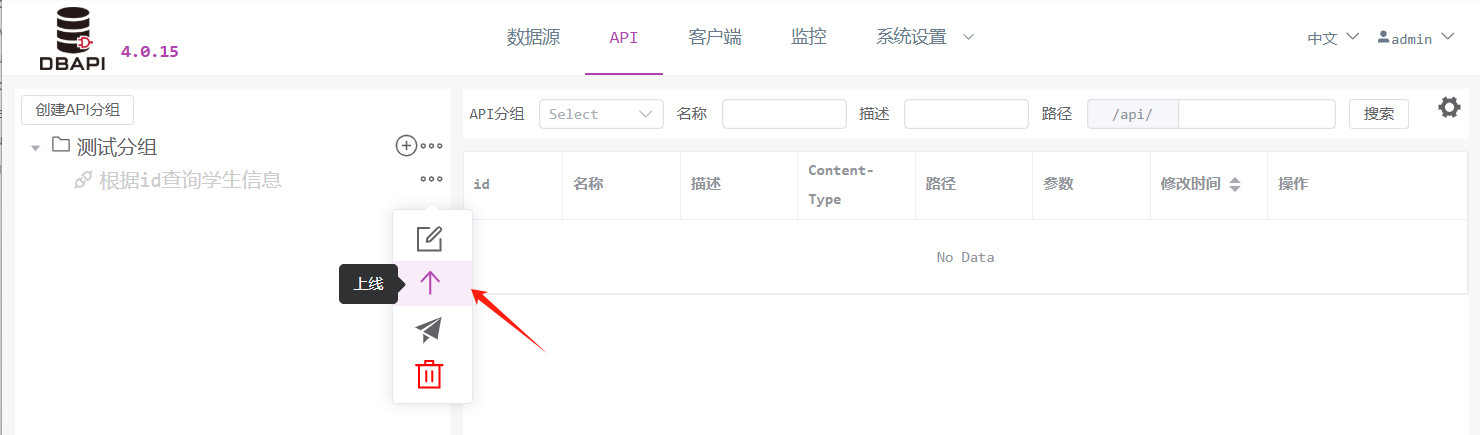
3. Publicación de la API
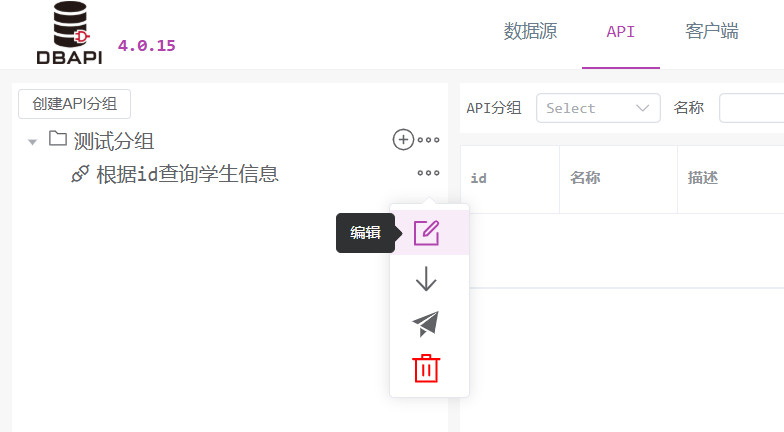
Haga clic en el botón "Más" junto a la API para mostrar la opción "Publicar", y seleccione "Publicar" para lanzar la API.
Haga clic en el botón "Más" junto a la API para mostrar la opción "Probar solicitud"; luego, seleccione "Probar solicitud" para acceder a la página de pruebas.
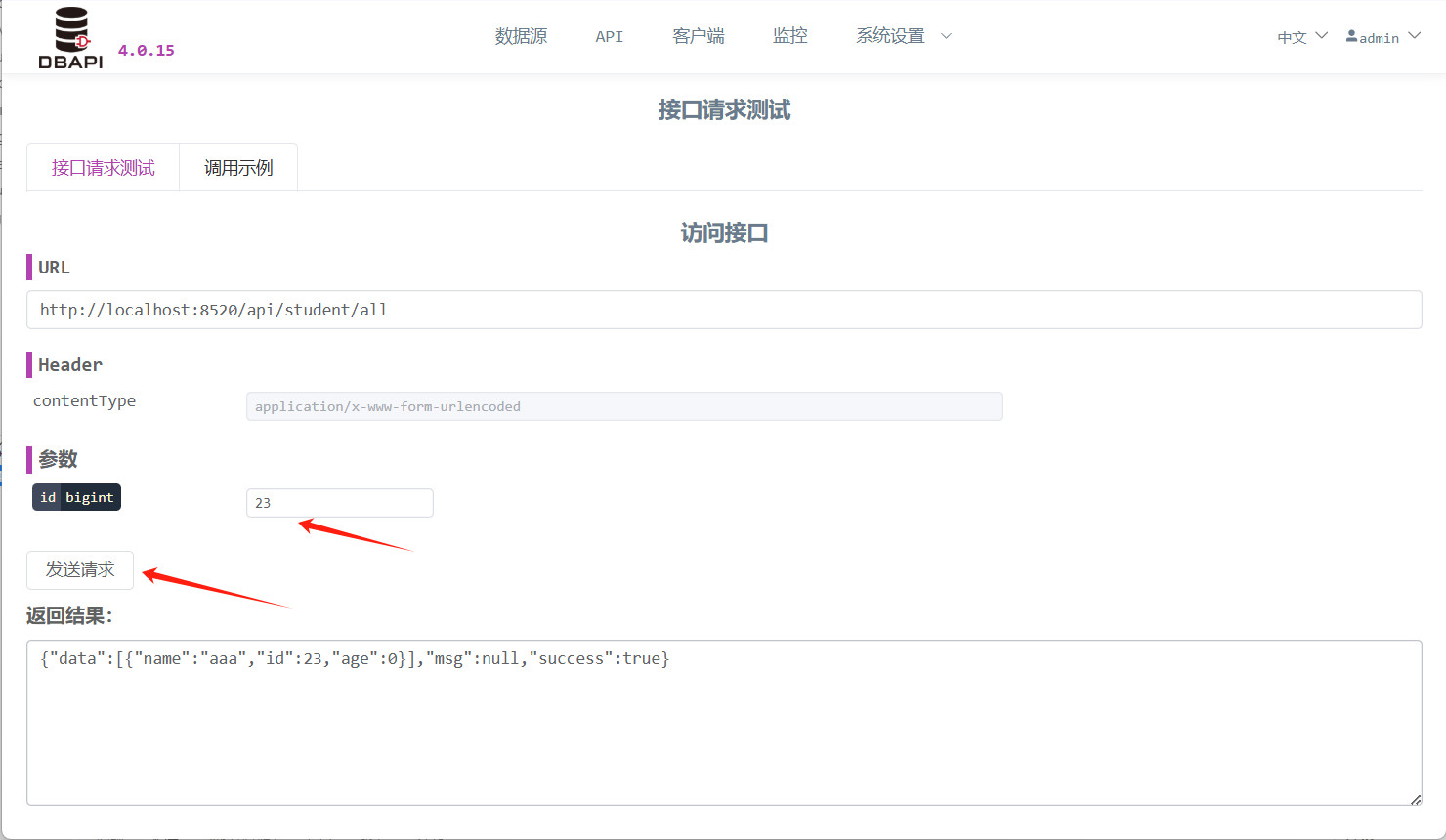
Haga clic en el botón "Enviar solicitud" para enviar la petición; si la solicitud contiene parámetros, asegúrese de completarlos correctamente.
Gestión de clientes
Haga clic en el menú de Clientes y seleccione "Crear cliente".
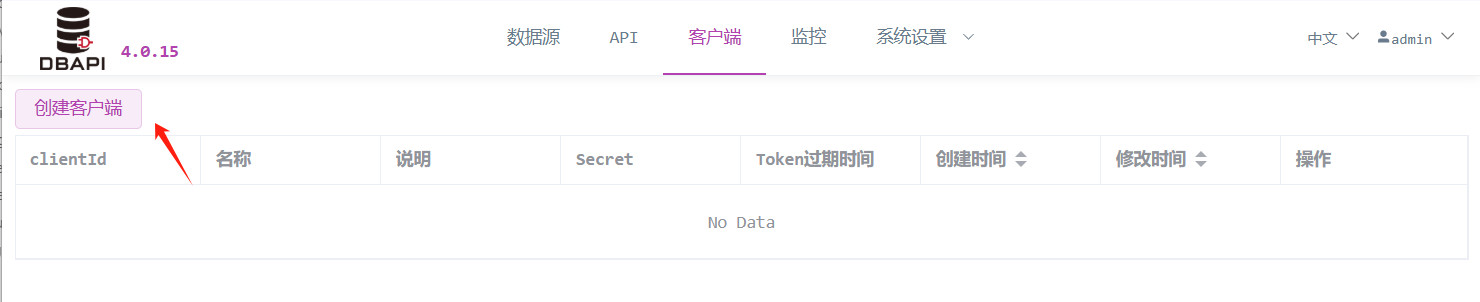
Complete la información del cliente y guarde los cambios.
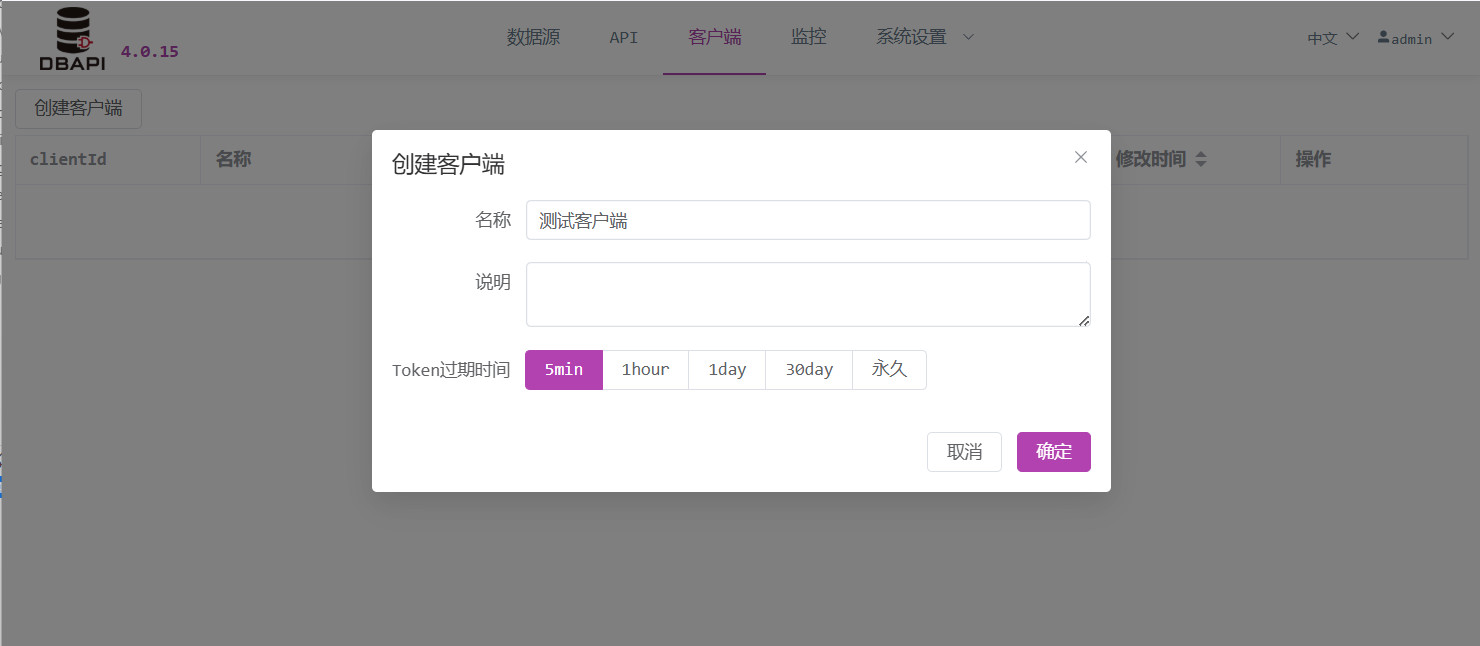
Tras crear un cliente, el sistema generará un clientId y una secret. El administrador del sistema deberá comunicar estos valores al cliente (el usuario que llama a la API).
El cliente utilizará su propio clientId y secret para acceder a la ruta http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxx, donde podrá obtener dinámicamente un token. Solo con este token el cliente podrá acceder a las APIs privadas (siempre que el administrador del sistema haya autorizado previamente dicho cliente para acceder a esa API privada).
Al crear un cliente, es imprescindible establecer un tiempo de expiración para el token; cada vez que el cliente solicite un nuevo token, este tendrá una fecha de caducidad determinada. Mientras esté dentro de ese período, el token anterior seguirá siendo válido para acceder a la API; pasado ese plazo, será necesario solicitar uno nuevo.
[!CONSEJO] Si desea que el token sea válido permanentemente, configure un tiempo de expiración muy largo, por ejemplo, 100 años.
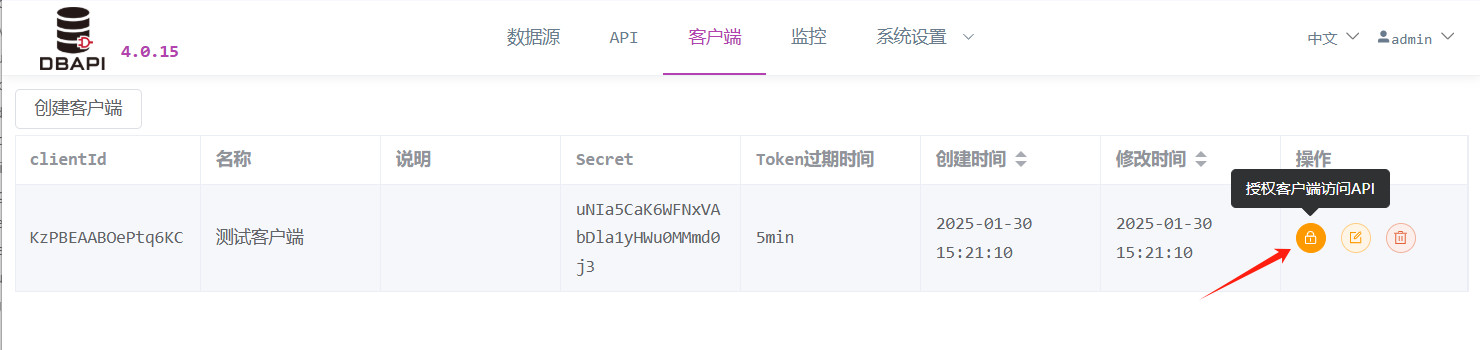
Haga clic en el botón "Autorizar" para otorgar permisos de acceso a la API al cliente.
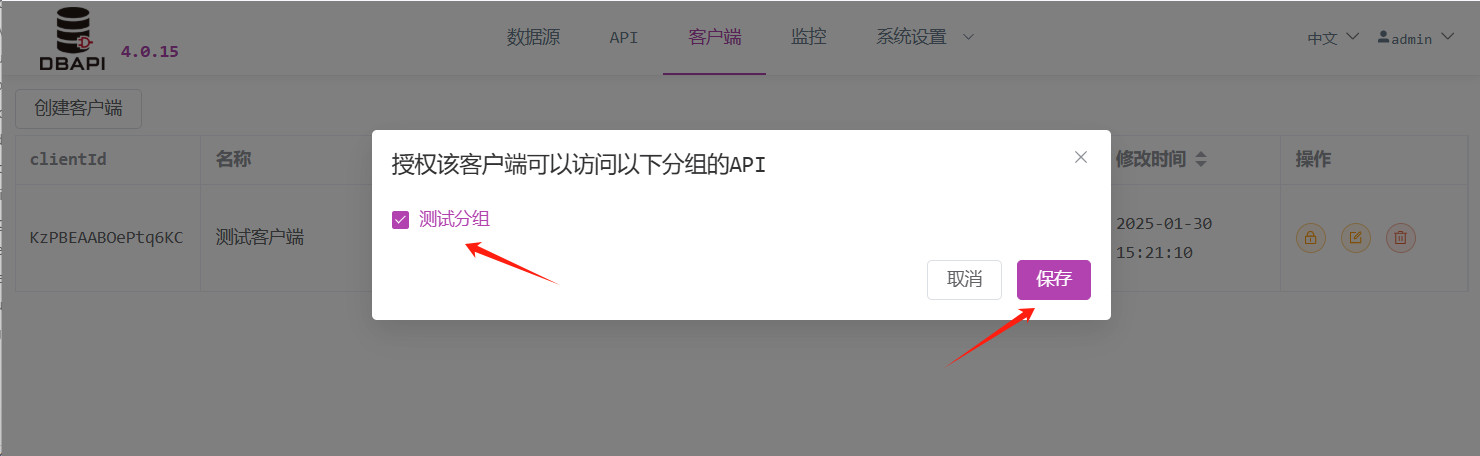
Seleccione el grupo al que desea otorgar permisos y guarde los cambios.
Instrucciones de uso del token
Interfaz para solicitar tokens:
http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxxAl solicitar una API privada, coloque el valor del token en el campo
Authorizationdel encabezado para poder acceder exitosamente. (Para APIs públicas, no es necesario configurar el encabezado.)Ejemplo de llamada en Python:
import requests
headers = {"Authorization": "5ad0dcb4eb03d3b0b7e4b82ae0ba433f"}
re = requests.post("http://127.0.0.1:8520/api/userById", {"idList": [1, 2]}, headers=headers)
print(re.text)Modifique la API anterior para convertirla en privada y luego vuelva a hacer clic en el botón "Probar solicitud".
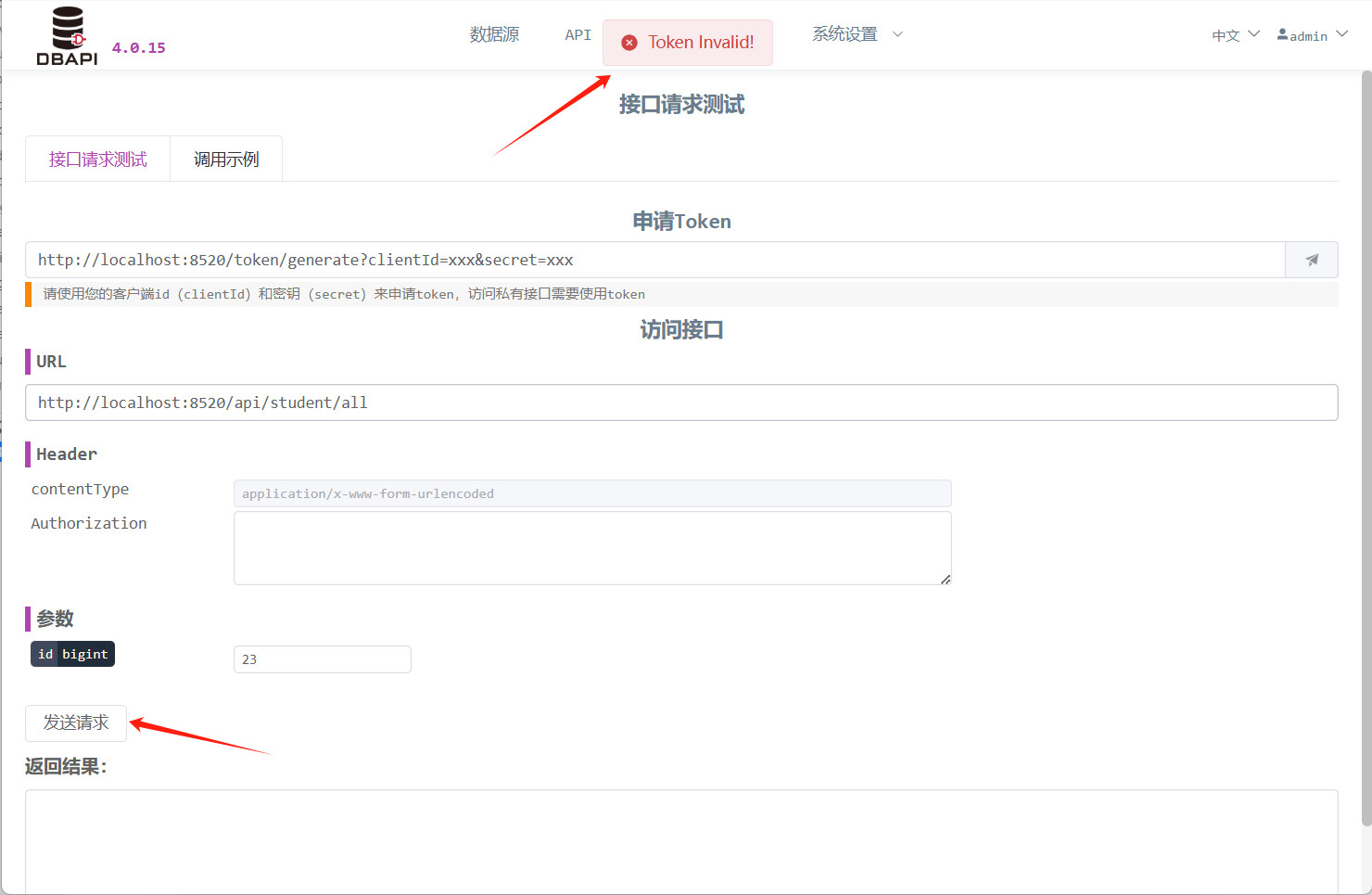
En este momento, al hacer clic en el botón "Enviar solicitud", descubrirá que la API no está accesible.
Introduzca nuevamente el
clientIdy elsecret, y haga clic en el botón para acceder a la API y obtener el token.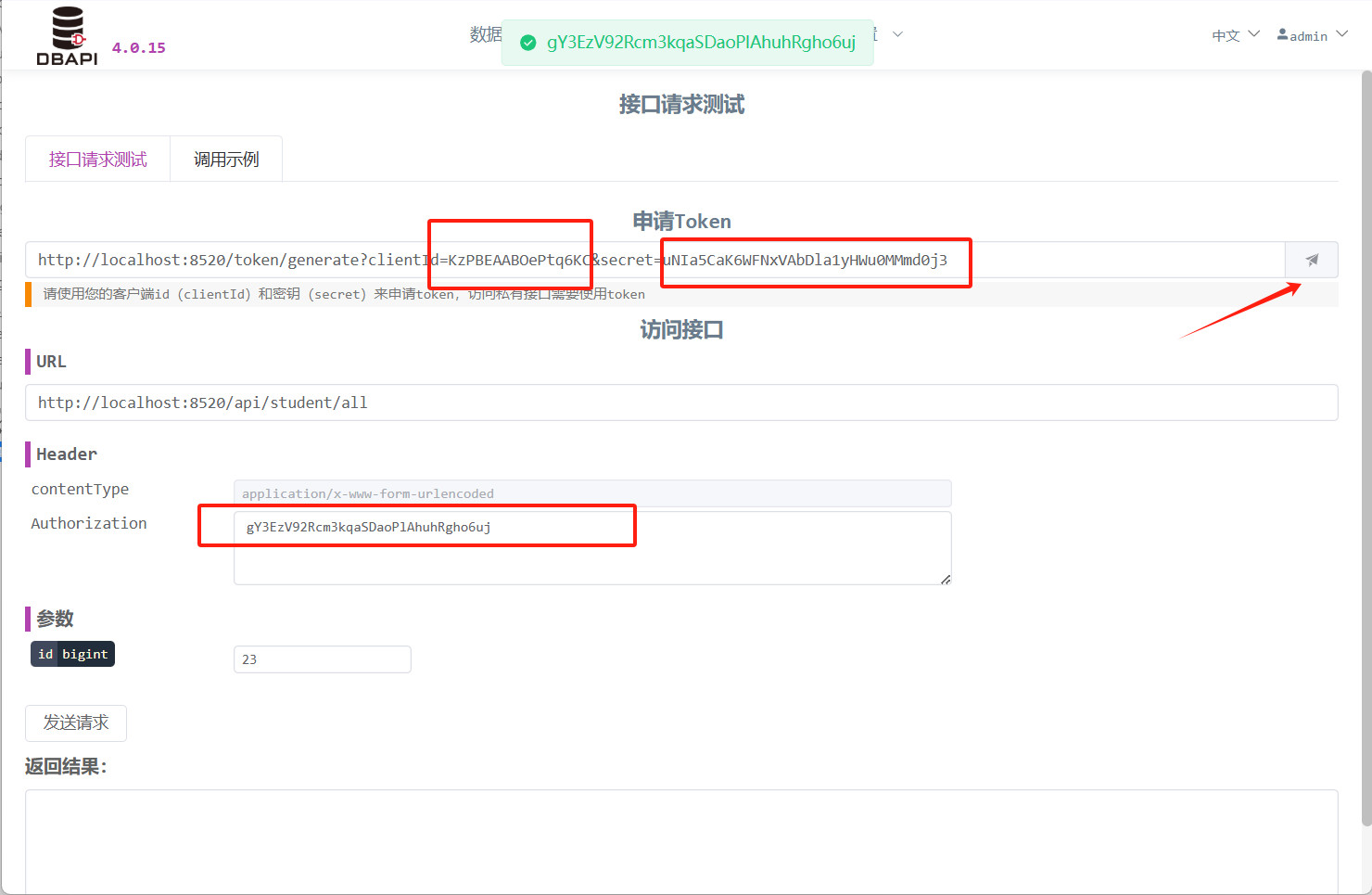
Coloque el token en el campo
Authorizationdel encabezado y vuelva a hacer clic en el botón "Enviar solicitud"; ahora la API estará accesible.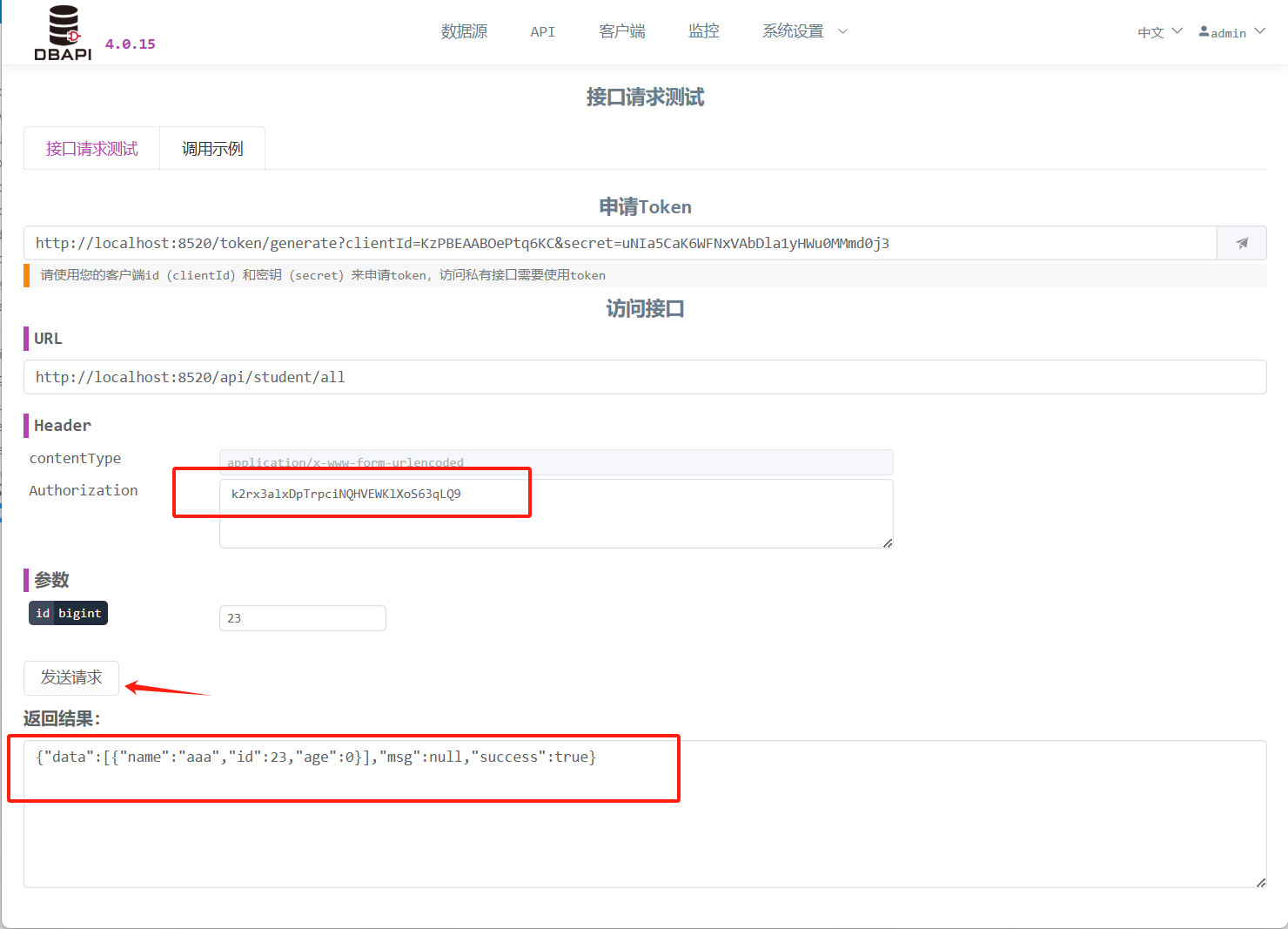
Configuración del firewall IP
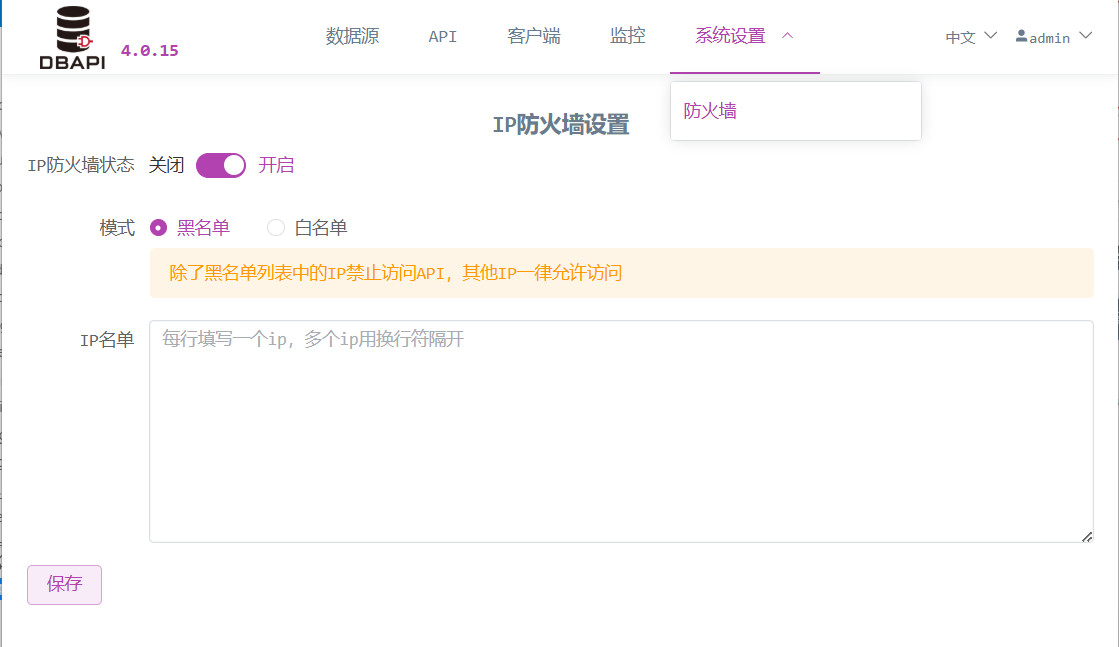
Activar el firewall permite bloquear direcciones IP específicas.
Monitoreo
DBAPI solo requiere una base de datos meta (postgresql/mysql/sqlite) para funcionar; sin embargo, si desea utilizar las funciones de monitoreo disponibles en la interfaz (como el registro de llamadas API, el volumen de tráfico, la tasa de éxito, etc.), deberá contar con otra base de datos de registro (que el usuario debe configurar por su cuenta) para almacenar los logs de acceso a las API. Se recomienda usar clickhouse/mysql/postgresql/doris, aunque también puede optar por otras bases de datos relacionales.
Actualmente se proporcionan scripts de inicialización para bases de datos de registro de clickhouse/mysql/postgresql, ubicados en el directorio sql.
[!NOTA] Si no necesita utilizar las funciones de monitoreo, puede omitir la configuración de la base de datos de registro y simplemente establecer
access.log.writer=nullen el archivoconf/application.properties. (Esta es la configuración predeterminada.)
Métodos de recopilación de logs
Recopilación desde archivos: Por defecto, DBAPI escribe los registros de acceso a las API en el archivo de disco
logs/dbapi-access.log. El usuario puede utilizar herramientas comodatax,flume, entre otras, para recopilar estos logs y cargarlos en la base de datos de registro.Conexión directa a la base de datos: Si en el archivo
conf/application.propertiesse configuraaccess.log.writer=db, DBAPI escribirá los registros de acceso a las API de forma asincrónica directamente en la base de datos de registro. Este método es adecuado para escenarios con volúmenes moderados de logs.Buffering mediante Kafka: Si en el archivo
conf/application.propertiesse configuraaccess.log.writer=kafka, DBAPI enviará los registros de acceso a las API a Kafka. En este caso, el usuario deberá recopilar los logs desde Kafka hacia la base de datos de registro; esta opción es ideal para escenarios con grandes volúmenes de logs, ya que Kafka permite gestionar el buffer de datos.
[!NOTA] Tenga en cuenta que, en este modo, es necesario especificar la dirección de Kafka en el archivo
conf/application.properties.Además, DBAPI incluye una herramienta integrada para consumir los logs de Kafka y cargarlos en la base de datos de registro. Utilice el script
bin/dbapi-log-kafka2db.sh.
Resumen del monitoreo
Haciendo clic en el menú de monitoreo, podrá visualizar los registros de las llamadas API.
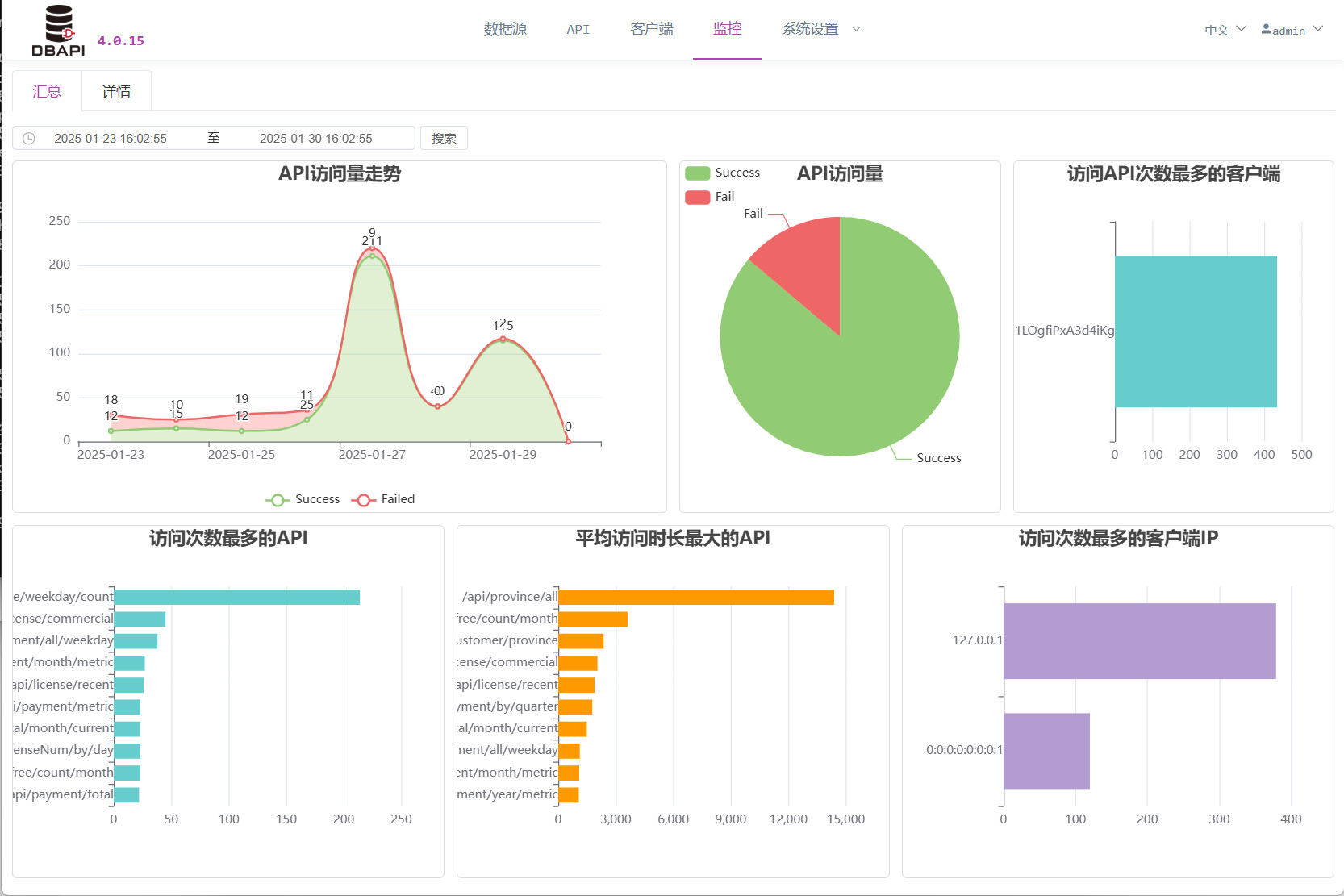
Visualización de los registros de llamadas a las API
Al seleccionar la pestaña "Detalles", podrá buscar los registros de las llamadas API.

Otras funcionalidades
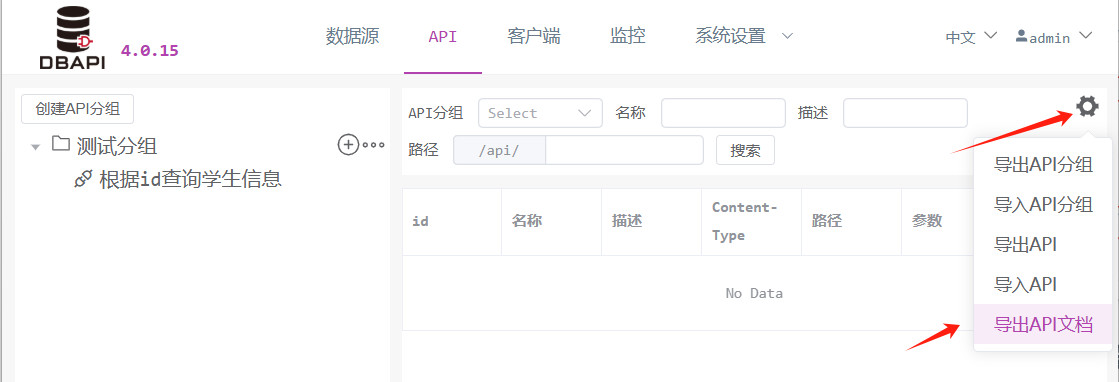
Exportación de la documentación de la API
En el menú de API, haga clic en el botón de herramientas y luego en el botón para exportar la documentación de la API.
Sistema de plugins
DBAPI ofrece cinco tipos de mecanismos de plugin. Puede descargar plugins desde el mercado de plugins. Si desea desarrollar sus propios plugins, consulte la documentación de plugins.
Plugin de caché
- Permite almacenar en caché los resultados de los ejecutores; por ejemplo, en el caso del ejecutor SQL, se puede guardar en caché los resultados de consultas SQL para evitar consultas repetidas a la base de datos y reducir la carga sobre ella.
- La lógica de caché debe ser implementada por el usuario, quien puede almacenar los datos en ehcache, redis, mongodb, entre otros.
- Cuando no se encuentra ningún dato en la caché, el sistema ejecuta la consulta correspondiente y, al mismo tiempo, guarda el resultado en la caché.
Escenarios con múltiples consultas SQL
Si un ejecutor SQL contiene varias sentencias, el plugin de caché encapsulará los resultados de todas ellas (si cada consulta tiene configurado un plugin de transformación, primero se aplicará dicha transformación) y almacenará el conjunto completo en caché.
Plugin de alertas
- Cuando se produce un error interno en la API, el plugin de alertas puede enviar notificaciones de advertencia mediante correo electrónico, SMS, DingTalk, Feishu, WeChat empresarial, entre otros canales.
- La lógica de generación de alertas debe ser definida por el usuario.
Plugin de transformación de datos
- A veces, SQL no puede obtener directamente los datos en el formato deseado; en estos casos, resulta más conveniente realizar ciertas transformaciones manuales mediante código. El usuario debe programar la lógica de transformación de datos.
- Por ejemplo, se pueden aplicar técnicas de ofuscación o anonimización a números de teléfono o números de tarjeta bancaria obtenidos tras una consulta SQL.
Escenarios con múltiples consultas SQL
Si un ejecutor SQL incluye varias sentencias, cada una tendrá su propio plugin de transformación de datos. Estos plugins siempre actúan sobre los resultados individuales de cada consulta SQL.
Plugin global de transformación de datos
- Por defecto, los datos devueltos por la API tienen el formato
{success: true, msg: xxx, data: xxx}. - En algunos casos, es necesario modificar el formato de la respuesta; por ejemplo, el framework de low-code frontal
AMISexige que las respuestas de la API incluyan un campostatus. En tales situaciones, se puede utilizar elplugin global de transformación de datospara ajustar el formato de toda la respuesta de la API.
[!NOTA] Diferencia entre el plugin de transformación de datos y el plugin global de transformación de datos El plugin de transformación de datos actúa sobre los resultados de los ejecutores (por ejemplo, transforma los resultados obtenidos tras ejecutar consultas SQL), mientras que el plugin global de transformación de datos modifica el formato de toda la respuesta de la API.
Plugin de procesamiento de parámetros
- Permite realizar operaciones personalizadas sobre los parámetros de solicitud.
- Por ejemplo, convertir todos los valores de los parámetros a mayúsculas.
- O bien, si la API recibe parámetros cifrados, el usuario puede implementar una lógica personalizada para descifrar dichos valores.
[!NOTA] Nota sobre compatibilidad de versiones El plugin de procesamiento de parámetros está disponible a partir de la versión Personal
4.0.16y de la versión Empresarial4.1.10.
Consideraciones importantes
Soporte para fuentes de datos
- Si desea utilizar Oracle u otras fuentes de datos, coloque manualmente el driver JDBC correspondiente en el directorio
extlibo en el directoriolibdespués de desplegar DBAPI (en caso de despliegue en clúster, asegúrese de añadir el jar en cada nodo). - Se recomienda colocar los drivers en el directorio
extlibpara facilitar su gestión centralizada.
Normas de escritura de SQL
- Al igual que la sintaxis dinámica de SQL de MyBatis, también admite los parámetros
#{}y${}, y puede consultar la documentación sobre la sintaxis dinámica de SQL. No es necesario incluir etiquetas externas como<select>o<update>; simplemente escriba el contenido SQL directamente. - Recuerde que, al igual que en MyBatis, los signos de menor que deben representarse como
<en lugar de<.