# DBAPI 使用指南
# 产品介绍
DBAPI 是面向数仓开发人员的低代码工具,只需在页面上编写 SQL 并配置参数,即可自动生成 HTTP 接口。它能帮助程序员快速开发后端数据接口,尤其适用于 BI 报表和数据可视化大屏的后端接口开发。
DBAPI 是整个企业数据接口的管理中心,是企业对外提供数据服务的管理平台。它提供了数据接口的动态创建发布功能,对接口的统一管理,并提供了对客户端的管理能力,可以监控客户端对接口的调用、控制客户端对接口的权限。
# 核心特性
- ✅ 开箱即用:无需编程,不依赖其他软件(单机模式仅需 Java 运行环境)
- ✅ 轻量部署:资源占用极低,2核4G服务器即可稳定运行
- ✅ 多平台支持:支持单机和集群模式,支持 Windows、Linux、macOS
- ✅ 动态配置:支持 API 和数据源的动态创建与修改,热部署无感知
- ✅ 权限控制:提供 API 级别访问权限管理,支持 IP 白名单/黑名单
- ✅ 广泛兼容:支持所有 JDBC 协议关系型数据库(MySQL、SQL Server、PostgreSQL、Oracle、Hive、达梦、人大金仓、Doris、OceanBase、GaussDB 等)
- ✅ 动态 SQL:支持 MyBatis 风格动态 SQL,提供 SQL 编辑、运行、调试一体化功能
- ✅ 全面支持:支持 Select/Insert/Update/Delete 语句及存储过程调用
- ✅ 事务管理:支持多 SQL 执行,可灵活控制事务开关
- ✅ 插件扩展:提供缓存、数据转换、失败告警、参数处理等丰富插件机制
- ✅ 便捷迁移:支持 API 配置导入导出,便于测试环境到生产环境迁移
- ✅ 参数处理:支持接口传参和复杂嵌套 JSON 传参,支持参数校验功能
- ✅ 监控统计:提供接口调用记录查询和访问信息统计功能
- ✅ 流量控制:支持 API 限流机制
- ✅ 流程编排:支持复杂 API 编排功能
- ✅ 开放集成:提供 OpenAPI 接口,便于与其他系统集成
# 基础概念
# 执行器
执行器是 API 业务逻辑的执行抽象,目前支持多种类型:
| 执行器类型 | 功能描述 |
|---|---|
| SQL 执行器 | 在数据库中执行 SQL 语句并返回结果 |
| Elasticsearch 执行器 | 执行 Elasticsearch DSL 查询并返回结果 |
| HTTP 执行器 | 作为网关代理转发 HTTP 请求并返回结果 |
个人版当前仅支持 SQL 执行器
# API 分组
用于对 API 进行分类管理,将业务相关的 API 归入同一分组,便于维护和查找。
# 客户端
指调用平台 API 的应用程序,如 Python、Java 等应用。每个客户端具有唯一标识 clientId 和密钥 secret,由系统管理员创建并分配 API 访问权限。
# 快速入门
# 系统登录
使用默认账号密码 admin/admin 登录系统。

# 数据源配置
进入数据源管理页面,点击"创建数据源"
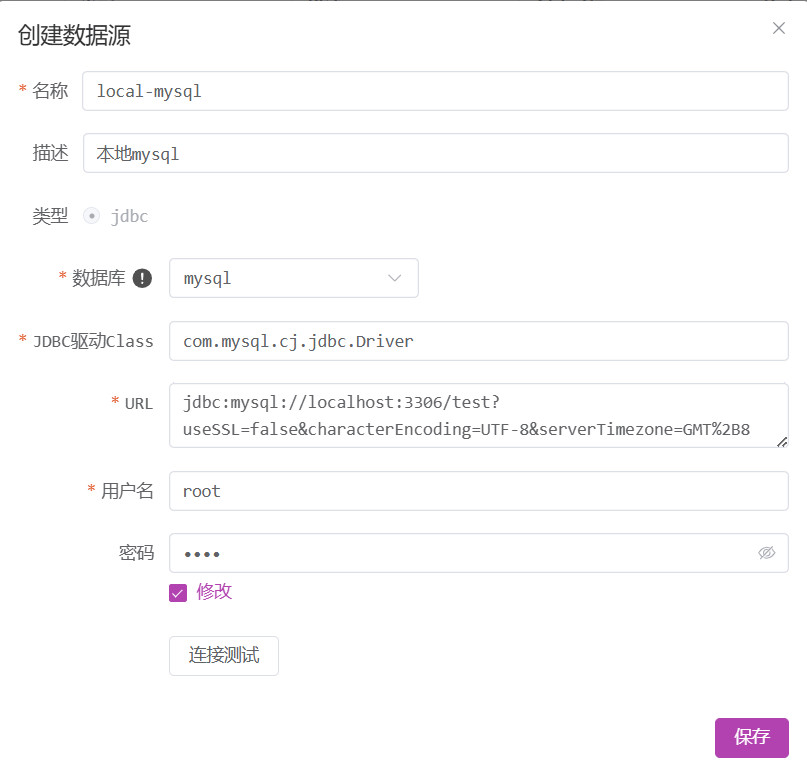
填写数据库连接信息并保存
保存后回到数据源页面,可对新建数据源进行编辑、删除操作
重要说明:
- 理论上支持所有 JDBC 协议数据库
- 使用其它类型数据库或者Oracle时,需手动填写 JDBC 驱动类名,并将相应 JDBC 驱动 JAR 包放入
extlib或lib目录后重启服务(集群模式需所有节点操作)lib目录已内置 MySQL/SQL Server/PostgreSQL/ClickHouse 驱动,版本不匹配时请手动替换- 推荐将自己的驱动 JAR 包放入
extlib目录以便统一管理
# API 创建流程
# 1. 创建 API 分组
进入 API 管理页面,点击左侧"创建 API 分组"
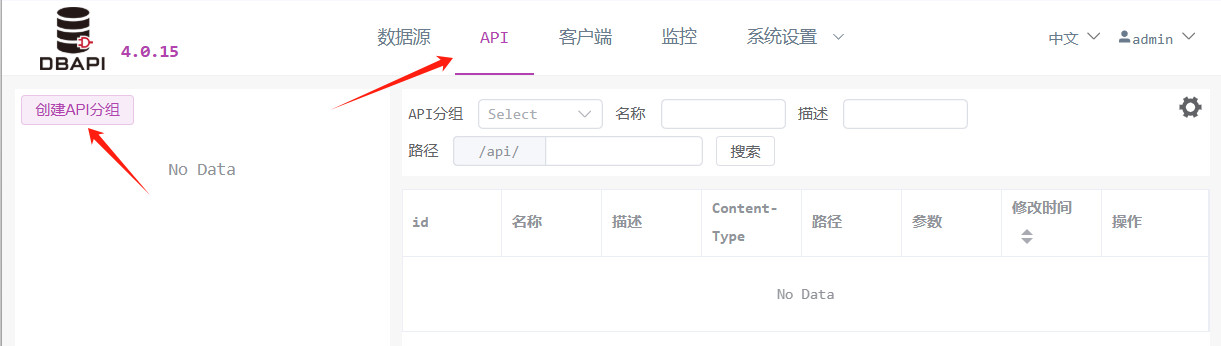
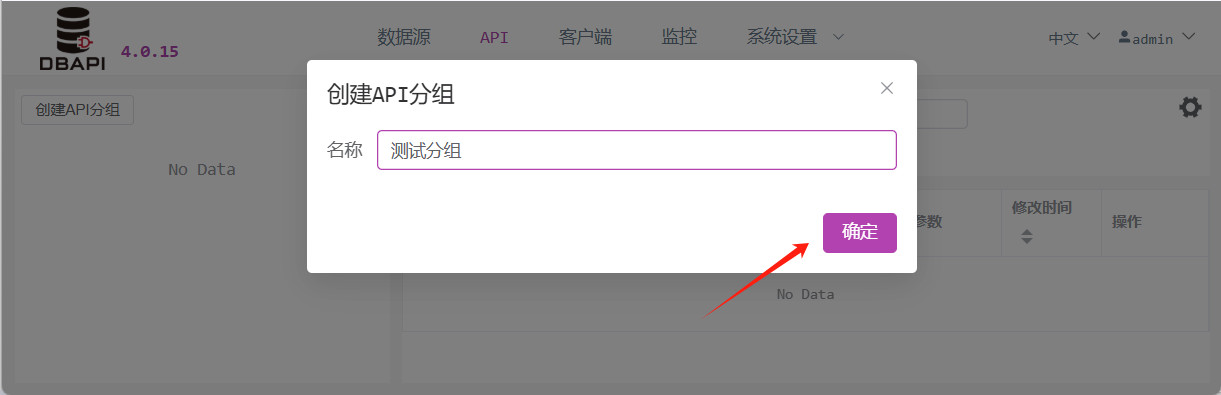
在弹窗中填写分组名称并保存
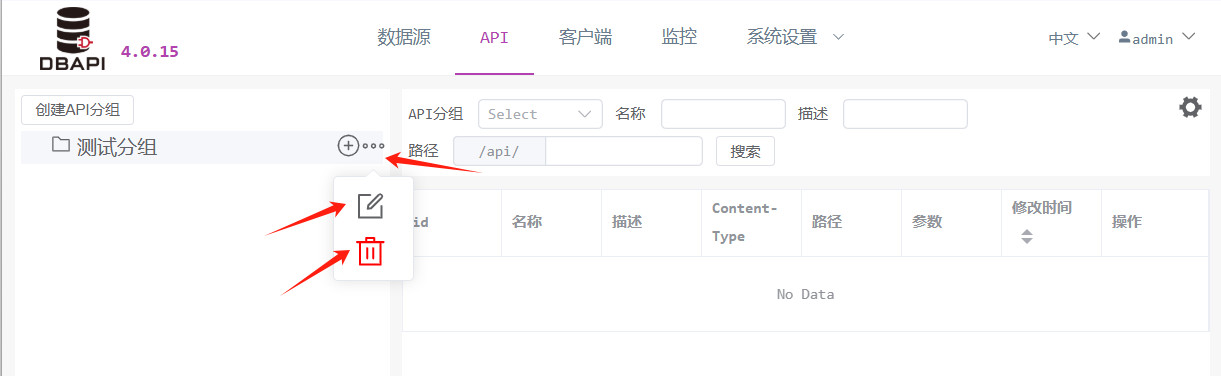
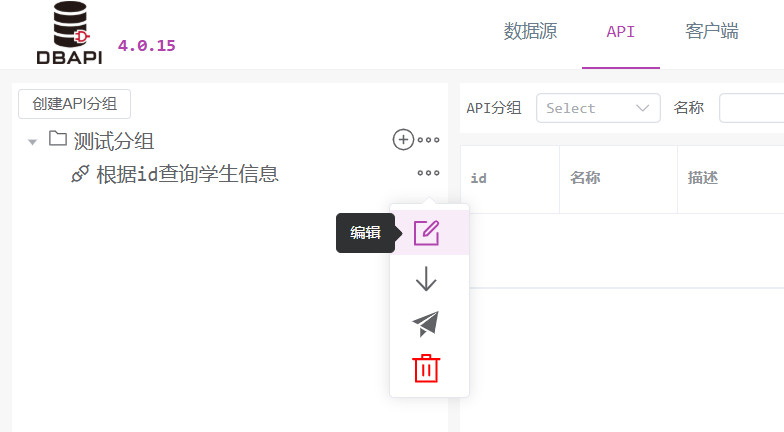
保存后发现左侧多了新的分组,点击分组上的更多按钮,可以编辑、删除分组
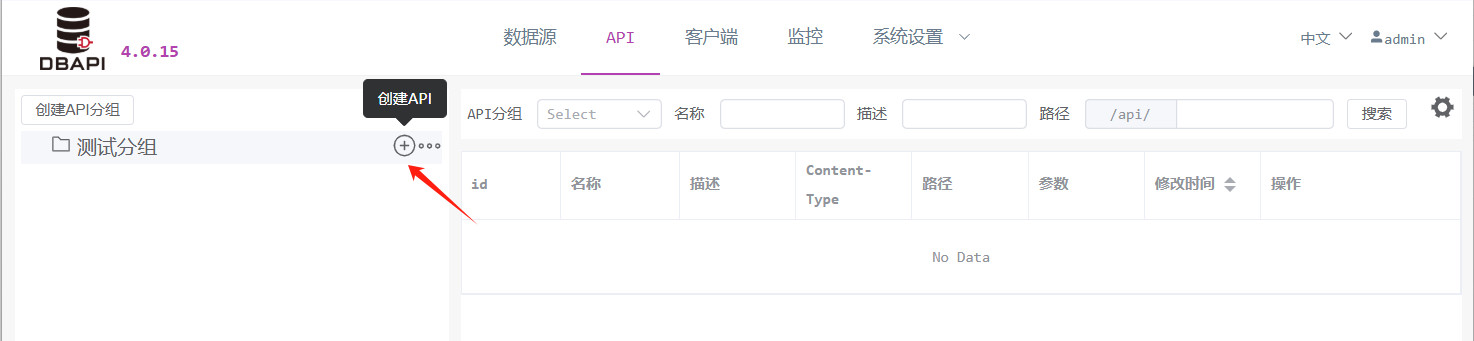
# 2. 创建 API
在目标分组中点击"创建 API"按钮进入配置页面
点击基本信息,填写 API 基础信息
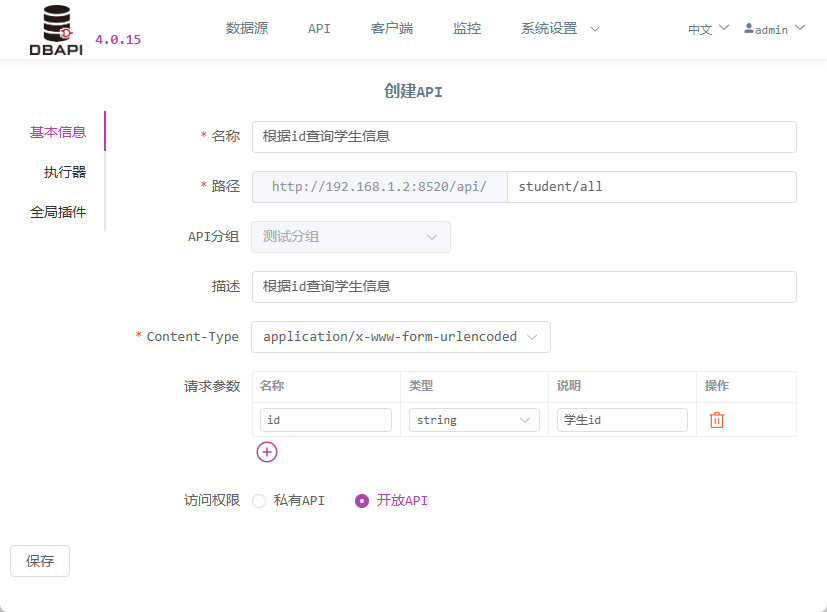
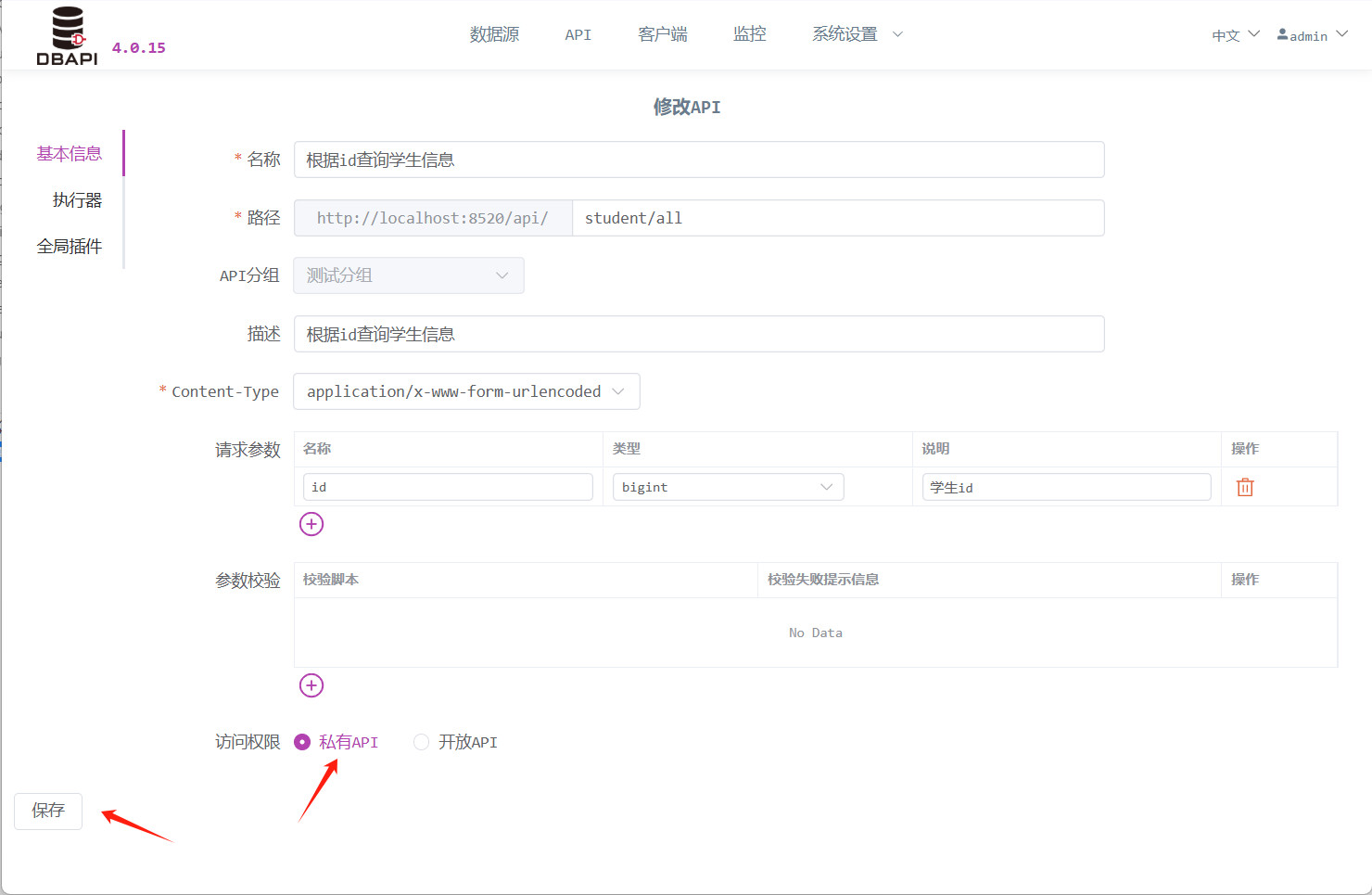
访问权限:开放接口可直接访问,私有接口需客户端申请 token 才能访问(这里我们先选择开放接口,方便后面测试)
Content-Type:如果是
application/x-www-form-urlencoded类型的 API,需要配置参数;如果是application/json类型的 API,需要填写 JSON 参数实例。点击执行器,填写执行器信息
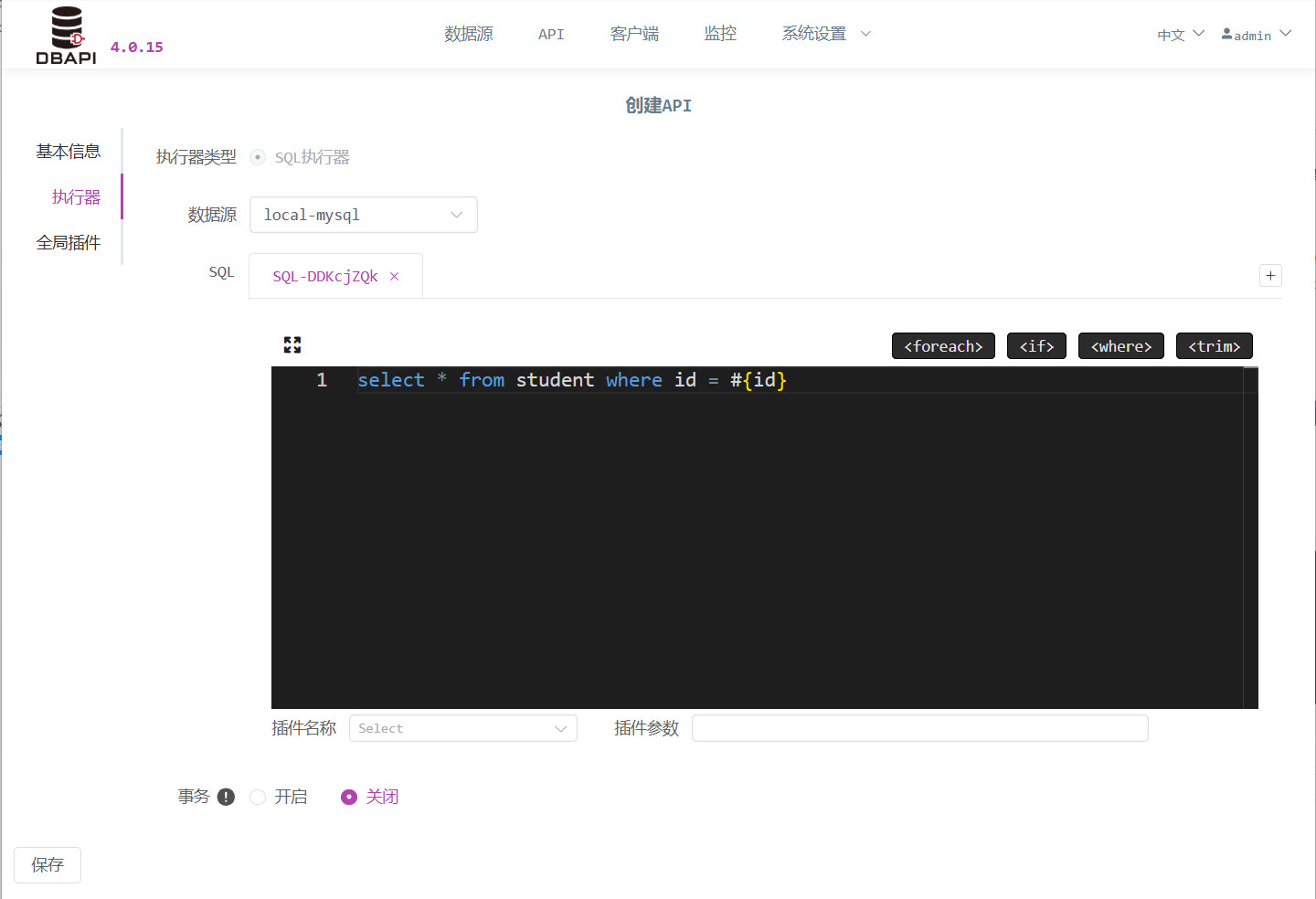
SQL 编写:采用 MyBatis 动态 SQL 语法(无需外层
<select><insert><delete><update>标签),参数使用#{}或${}表示,动态 SQL 语法可参考动态 SQL 语法文档事务控制:默认关闭事务,如果是 insert/update/delete 语句,建议开启事务,开启事务后如果 SQL 执行失败事务会回滚。如果 API 内有多条 SQL,开启事务后多条 SQL 是放在一个事务内执行的
重要提示:如果是 HIVE 等不支持事务的数据库,请不要开启事务,否则会报错
数据转换:如果需要数据转换,就填写数据转换插件的 Java 类名,不填写表示不转换。插件如果需要传参数就填写参数。
多SQL支持:点击添加按钮可以新增 SQL,一个 API 内可以执行多条 SQL,最后的多个结果封装后一起返回,比如分页查询,一个接口内既要查询详情也要查询总条数。一个 SQL 编写窗口内只能写一条 SQL。
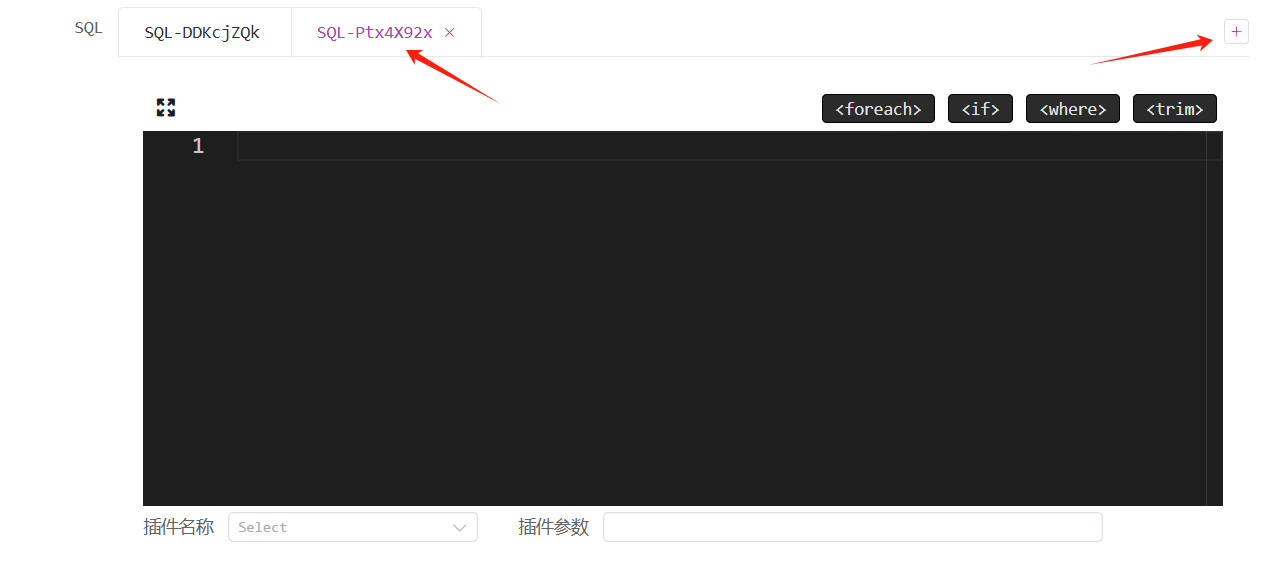
重要说明:如果一个执行器内包含多条 SQL,那么每条 SQL 会对应一个数据转换插件配置,数据转换插件永远是针对单条 SQL 查询结果进行转换
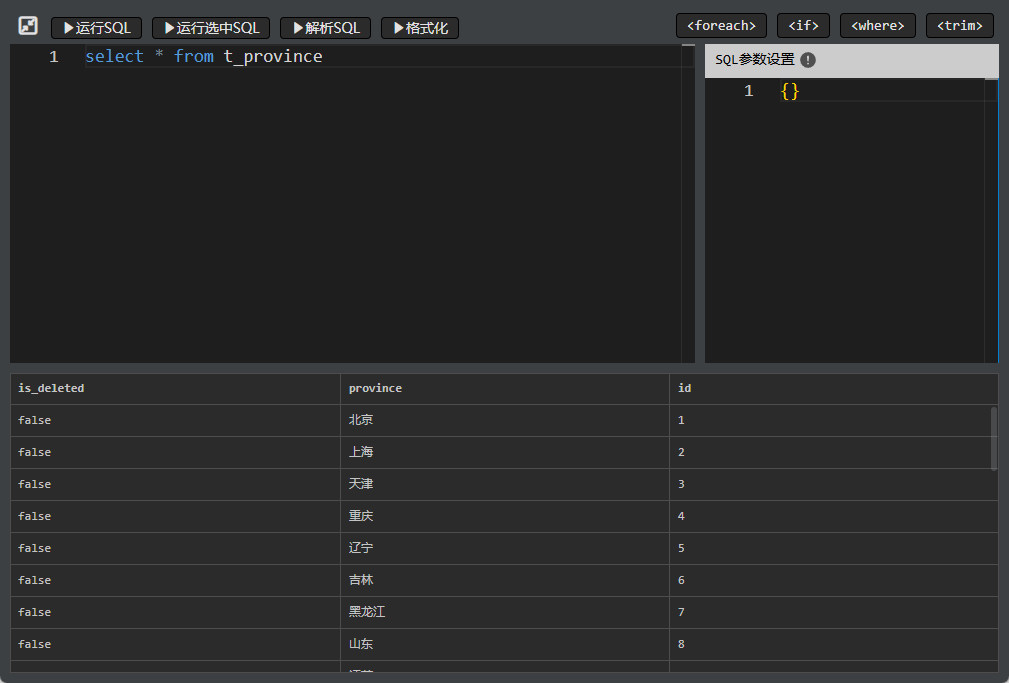
点击窗口最大化按钮,进入 SQL 调试界面
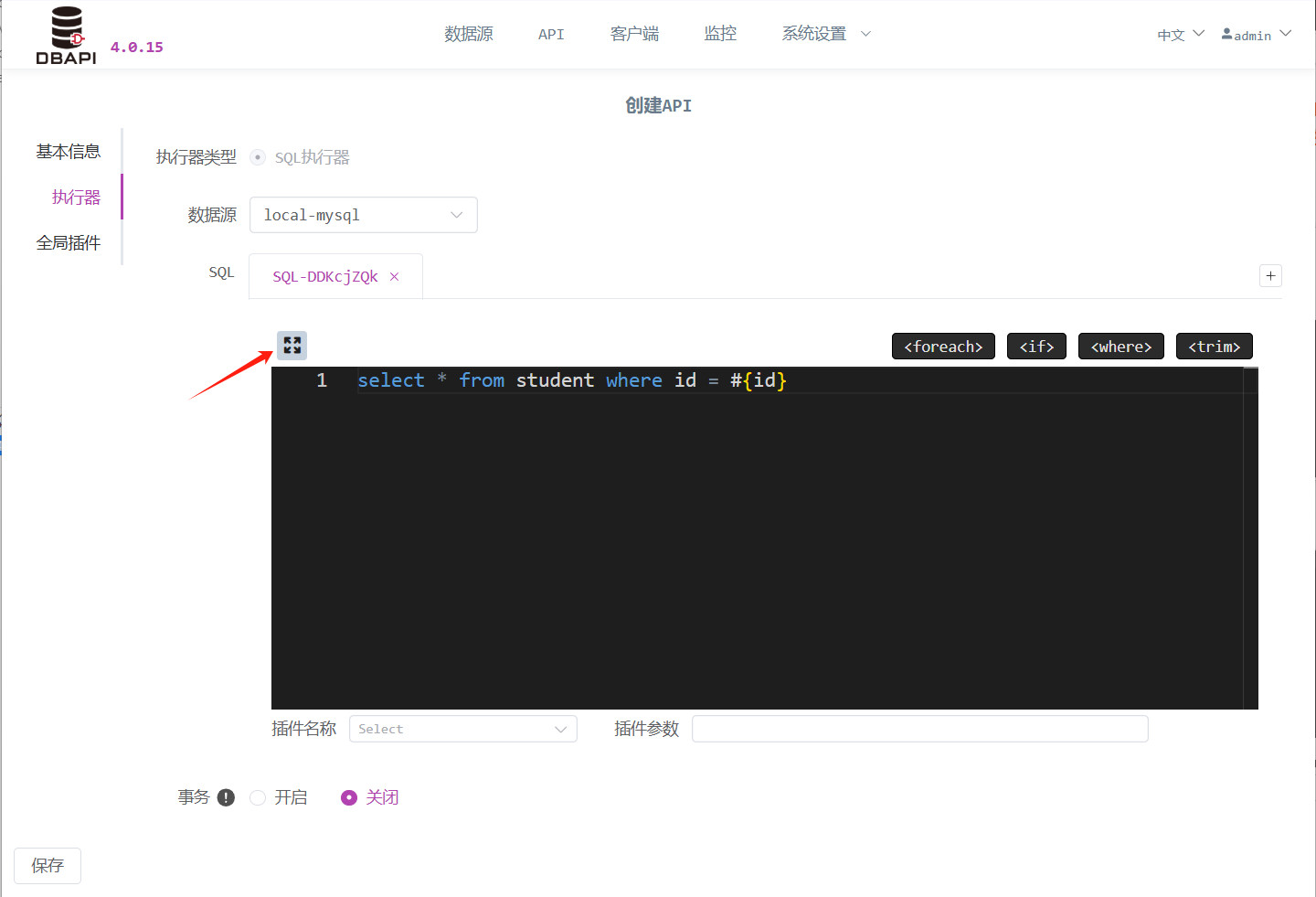
点击运行 SQL,可以执行 SQL,如果 SQL 中有参数需要设置参数
点击全局插件,填写全局插件信息
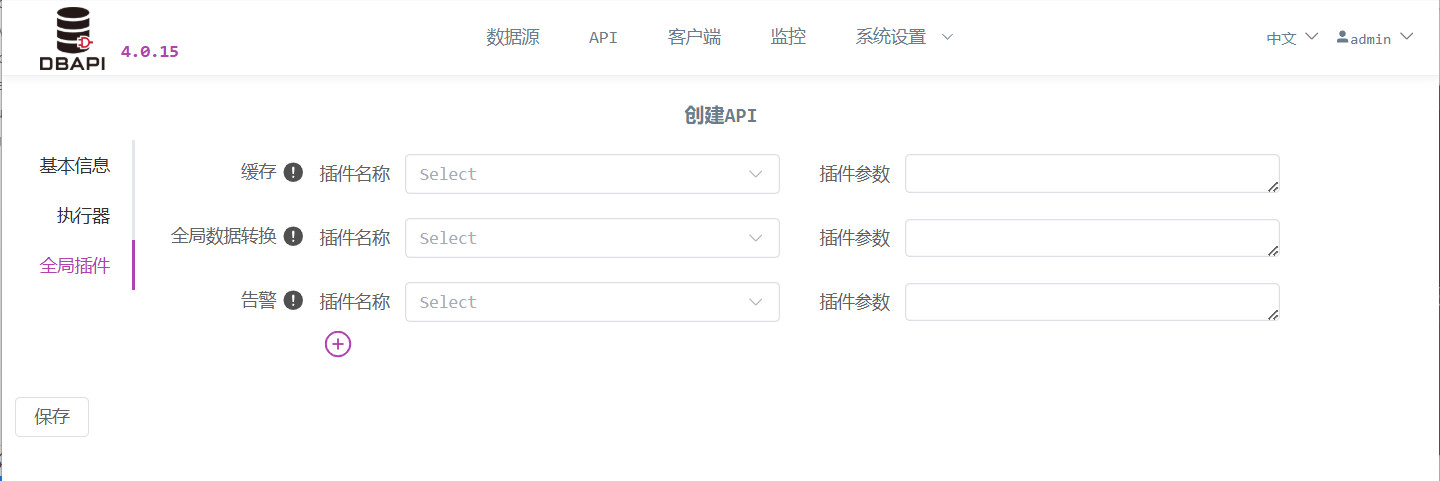
缓存:如果需要数据缓存,就填写缓存插件的 Java 类名,不填写表示不开启缓存。插件如果需要传参数就填写参数。
告警:如果 API 执行失败需要告警的话,就填写告警插件的 Java 类名,不填写表示不开启失败告警。插件如果需要传参数就填写参数。
全局数据转换:如果需要数据转换,就填写数据转换插件的 Java 类名,不填写表示不转换。插件如果需要传参数就填写参数。
参数处理:如果需要参数处理,就填写参数处理插件的 Java 类名,不填写表示不处理。插件如果需要传参数就填写参数。
点击保存即可创建 API,点击 API 菜单即可回到 API 列表页面
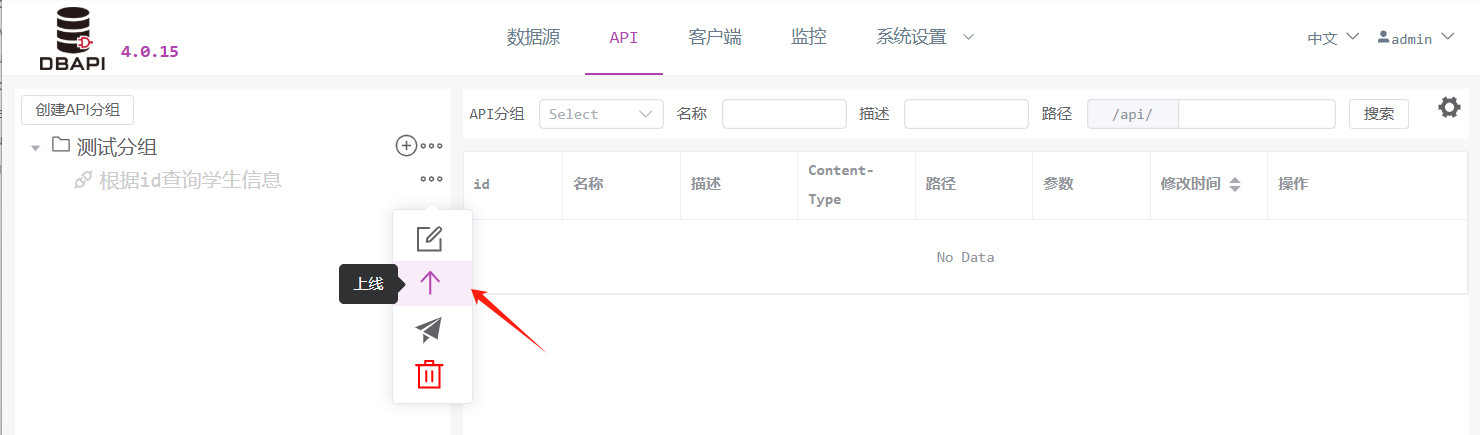
# 3. API 发布
点击 API 上的更多按钮,展开了上线按钮,点击上线按钮发布 API
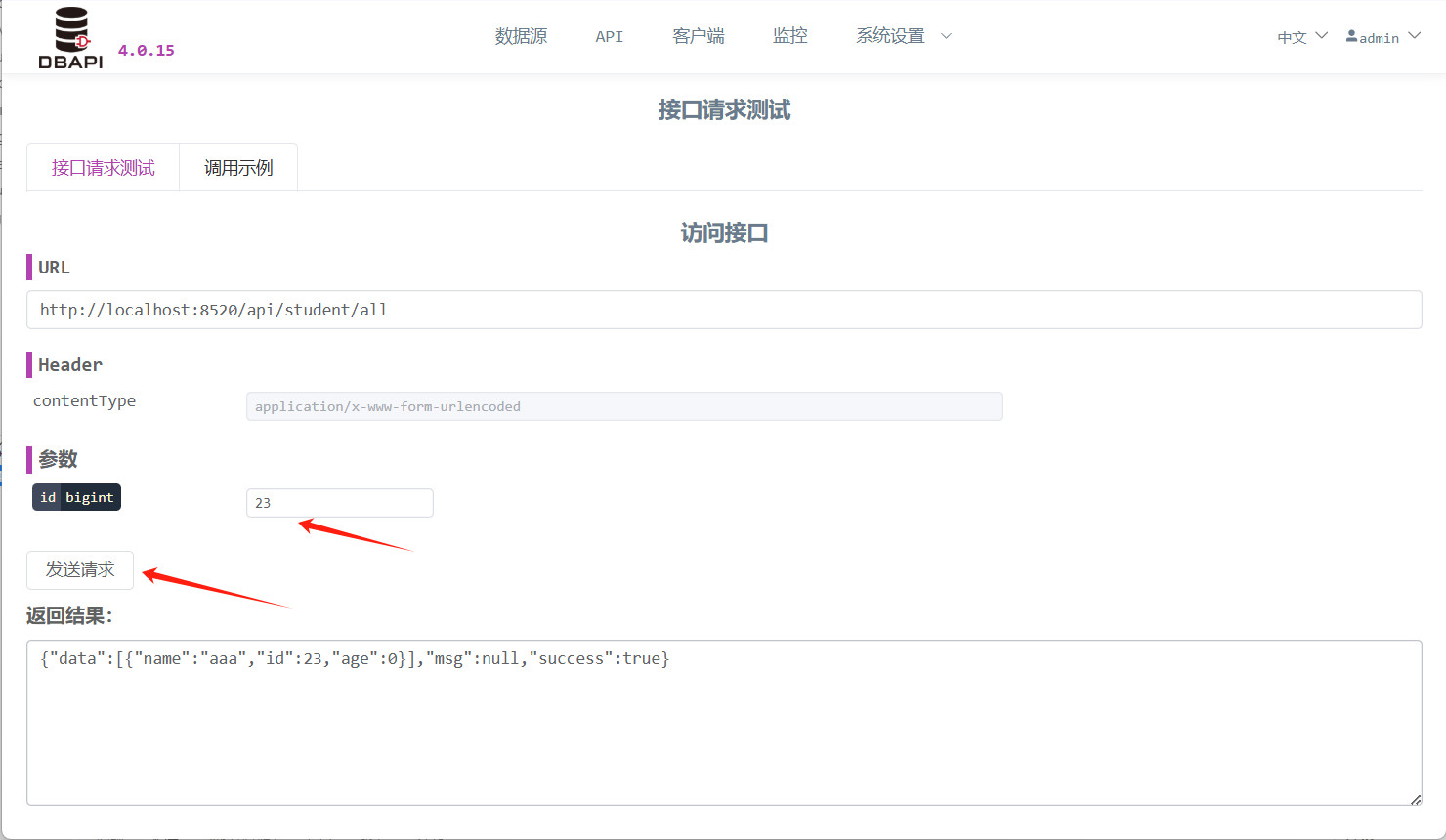
点击 API 上的更多按钮,展开了请求测试按钮,点击请求测试按钮进入请求测试页面
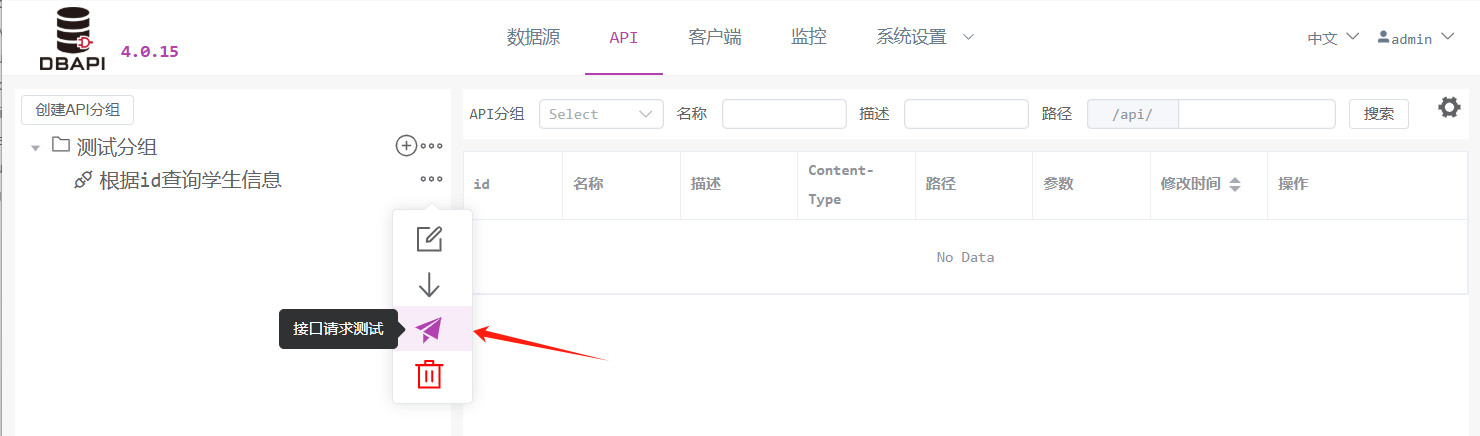
点击发送请求按钮,可以发起请求,如果有参数需要填写参数
# 客户端管理
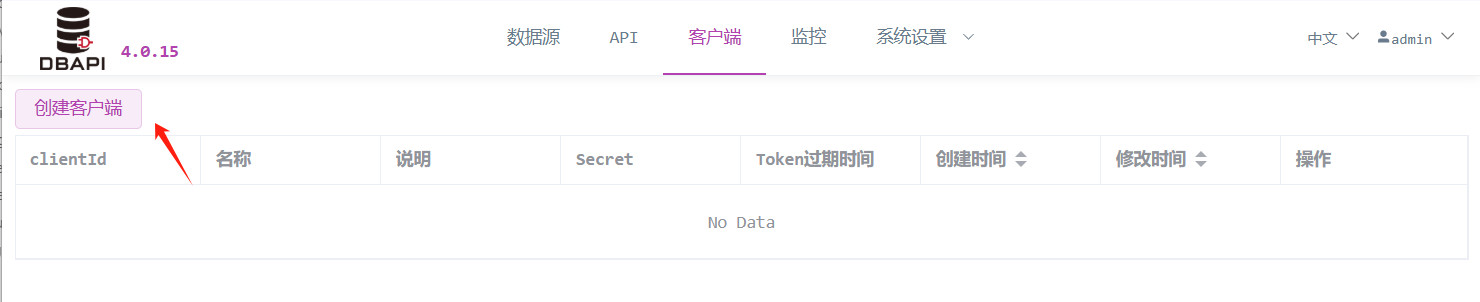
点击客户端菜单,点击创建客户端按钮
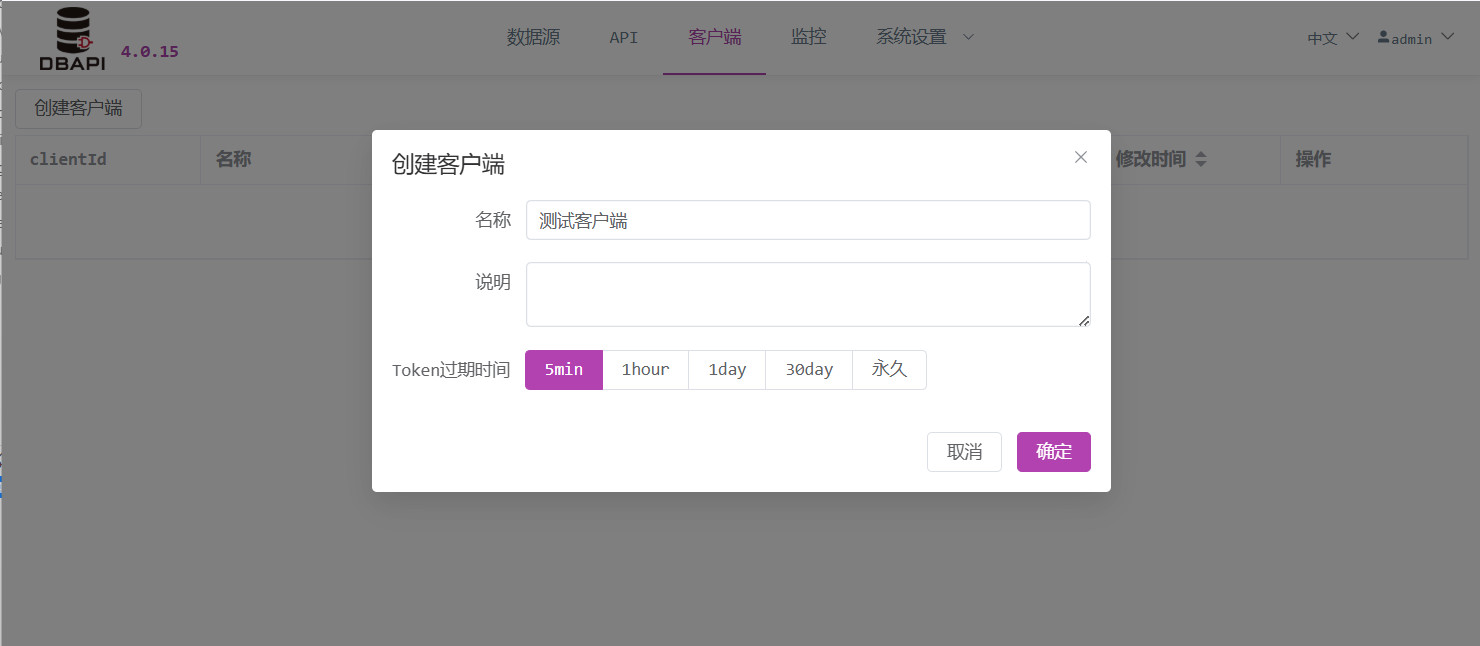
填写客户端信息,保存
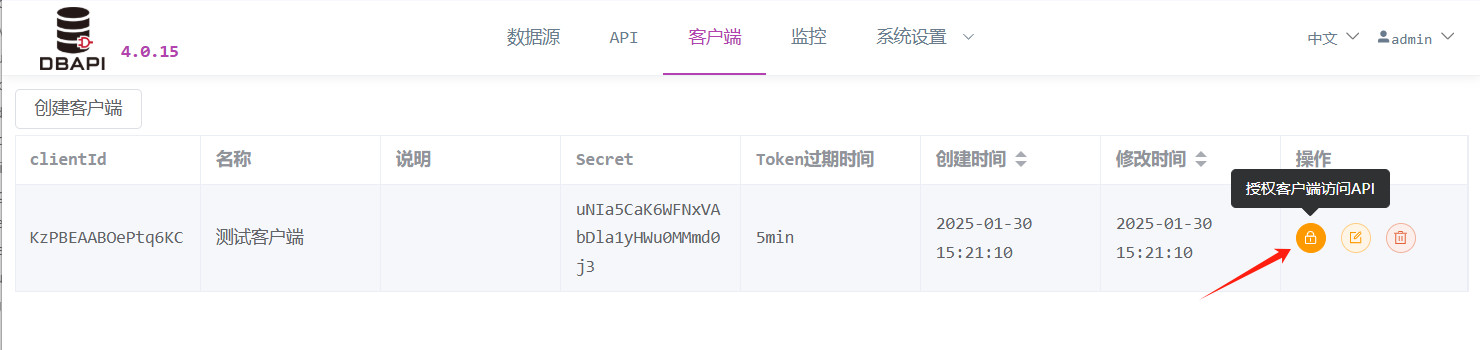
创建客户端会生成 clientId 和 secret,系统管理员需要将 clientId 和 secret 告知客户端(API 调用方)。
客户端使用自己的 clientId 和 secret 访问 http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxx 接口可以动态获取 token,客户端使用这个 token 才能访问私有 API(前提是系统管理员已经对该客户端授权了访问此私有 API)。
创建客户端必须设置 token 过期时间,以后客户端每次申请的 token 就会有相应的过期时间,在这个有效期内,使用上一次申请的 token 去访问 API 都是有效的。否则过了这个过期时间,就要重新申请 token。
如果想让token永久有效,请将过期时间设置为一个很大的值,比如100年
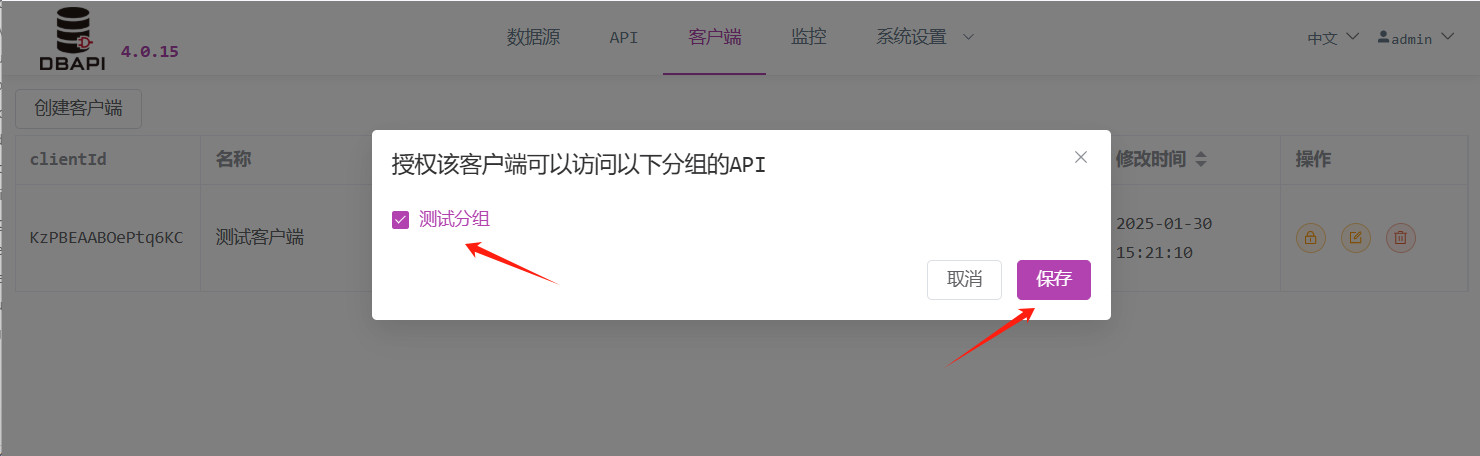
点击授权按钮,对客户端进行授权 API
选择需要授权的分组,保存
# Token 使用说明
token 申请接口:
http://192.168.xx.xx:8520/token/generate?clientId=xxx&secret=xxx请求私有接口时,需要把 token 值放入 header 的
Authorization字段中携带,才可以访问成功。(如果是开放接口,不需要设置 header)Python 调用示例:
import requests
headers = {"Authorization": "5ad0dcb4eb03d3b0b7e4b82ae0ba433f"}
re = requests.post("http://127.0.0.1:8520/API/userById", {"idList": [1, 2]}, headers=headers)
print(re.text)
修改之前的 API 为私有接口,然后再点击请求测试按钮
此时点击发送请求按钮,发现 API 不可访问
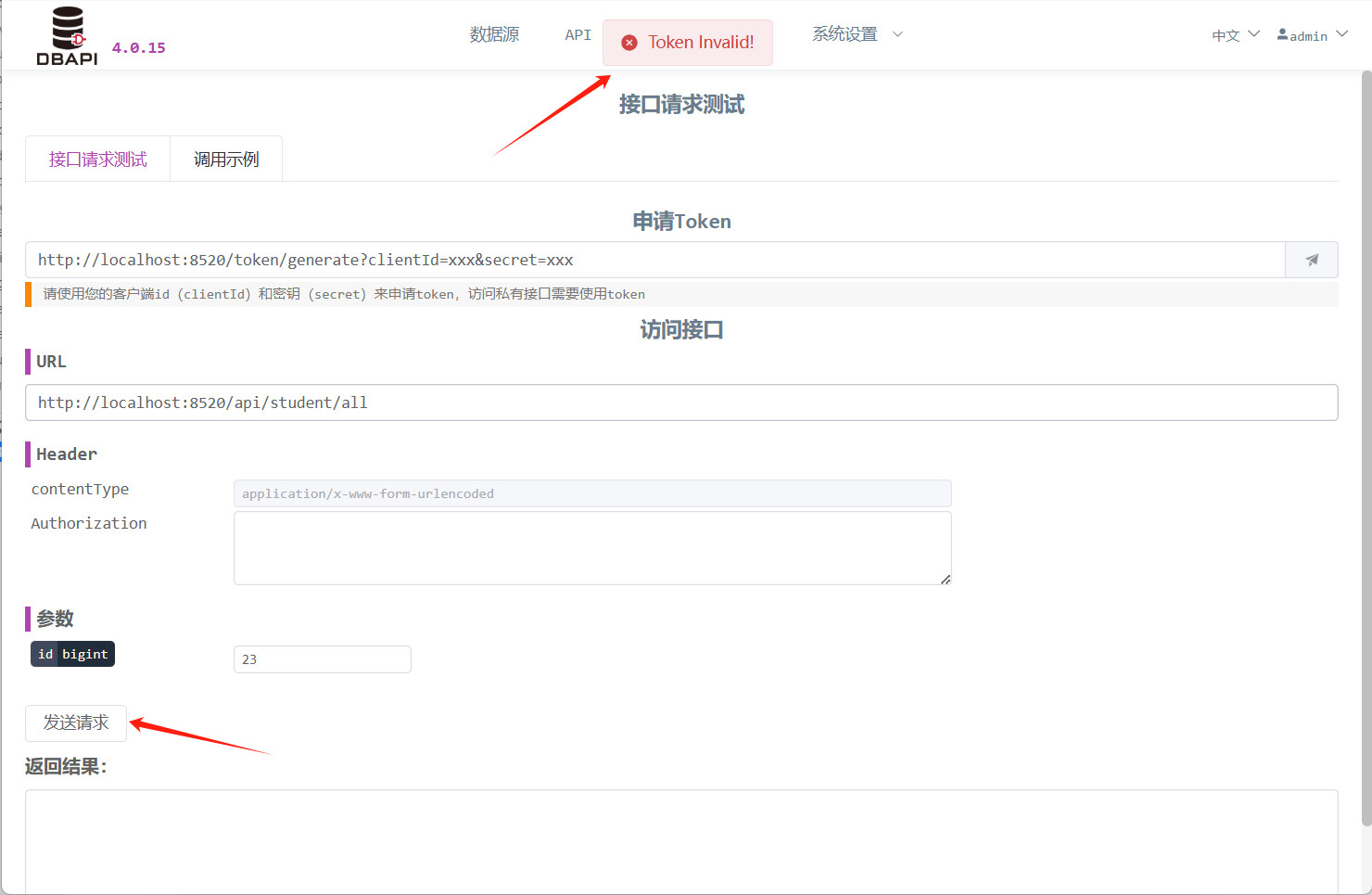
填入
clientId和secret,点击按钮访问接口获取token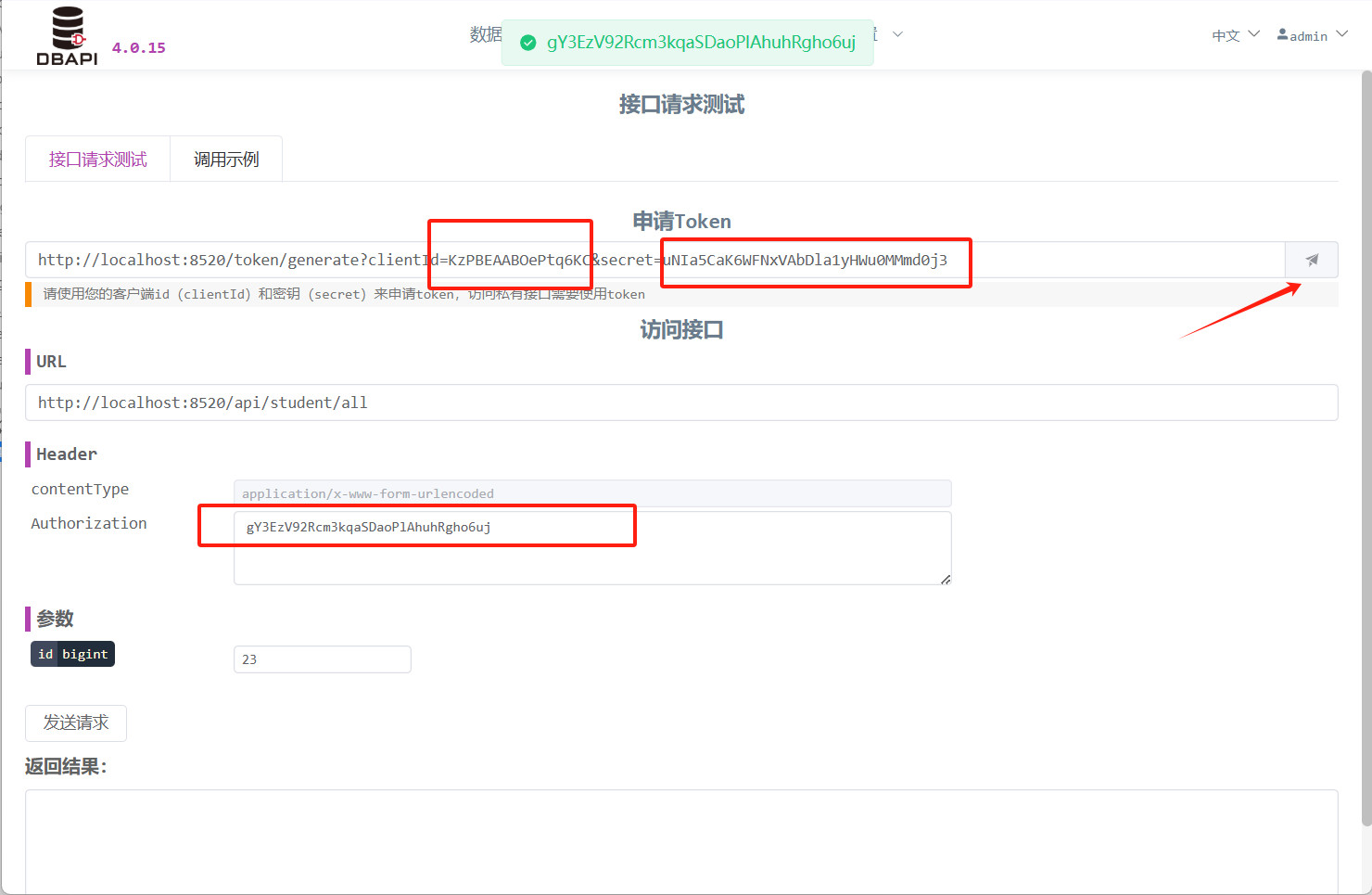
将
token填入header的Authorization字段,点击发送请求按钮,发现 API 访问成功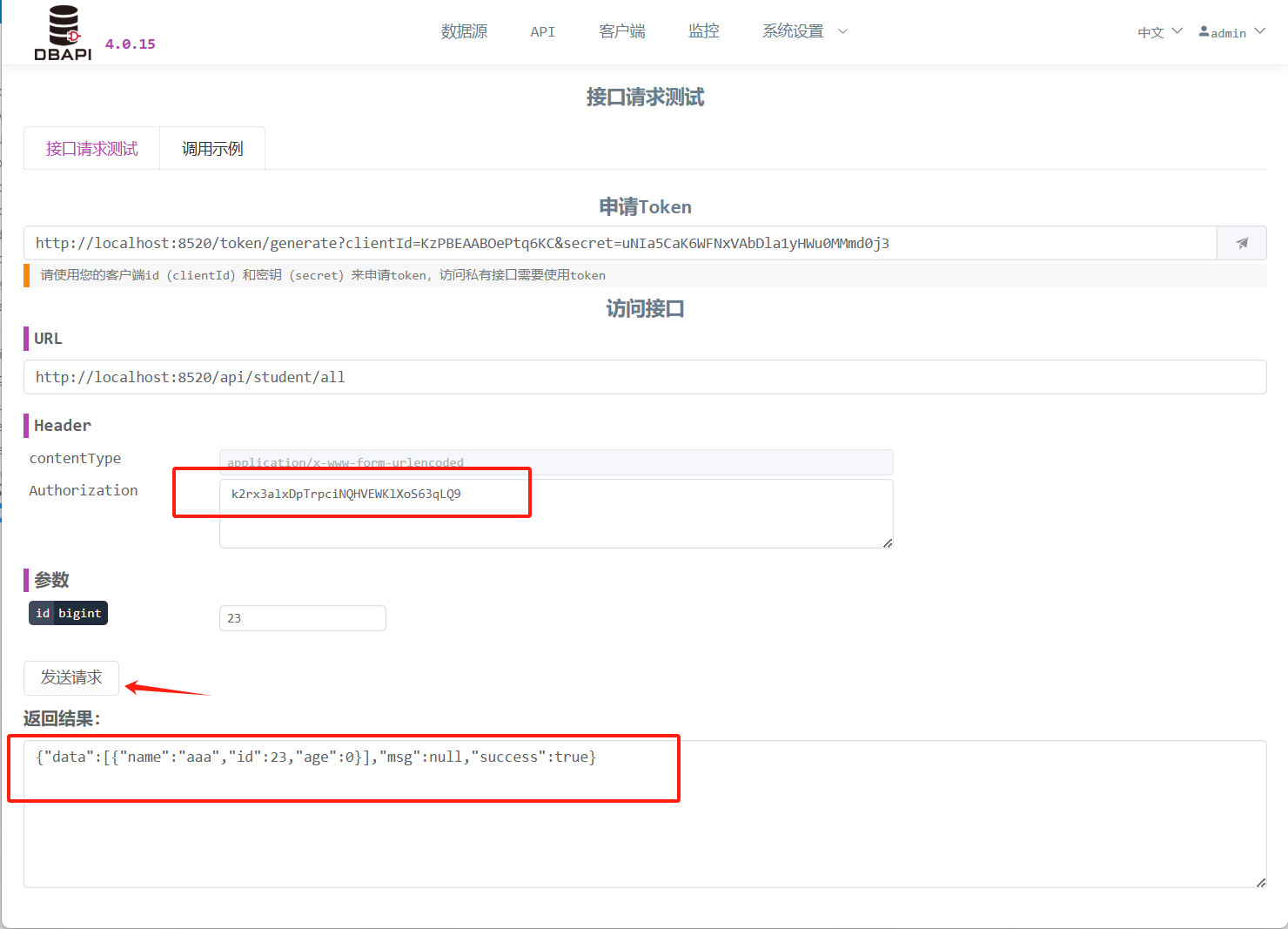
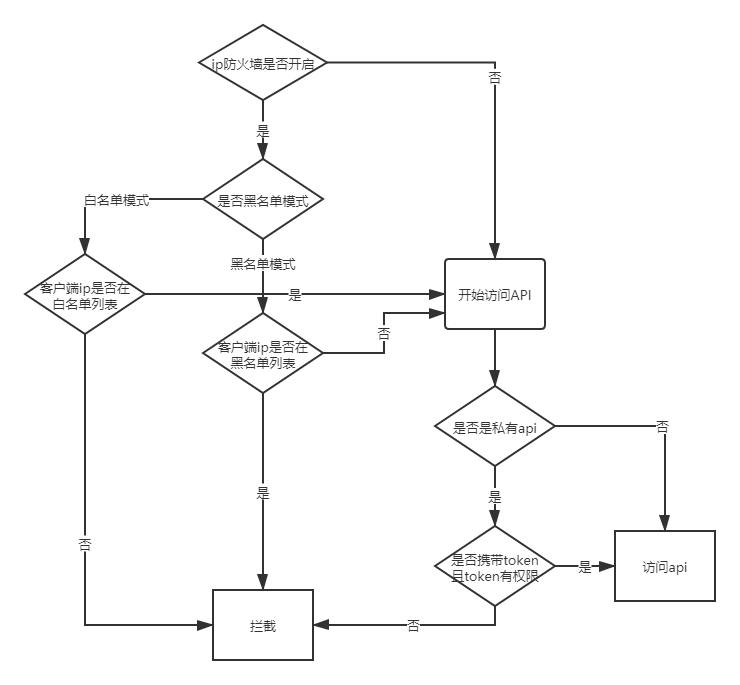
# IP 防火墙设置
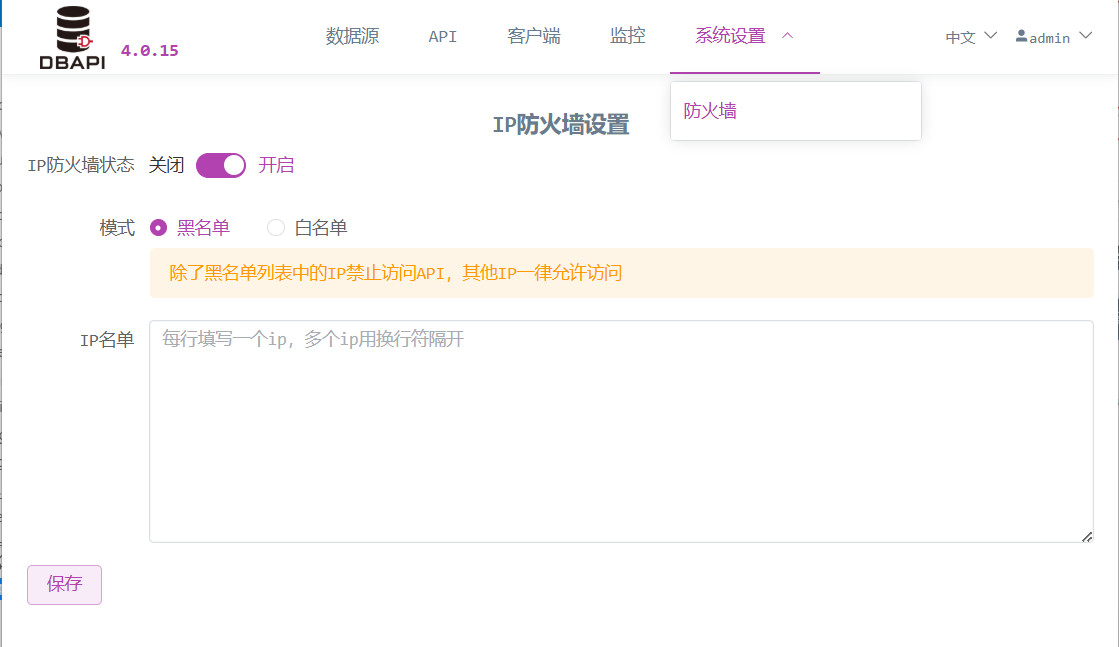
开启防火墙可以对 IP 进行拦截
# 监控
DBAPI 只依赖元数据库(mysql/sqlite)就可以使用,但是如果您还需要使用页面上的监控功能(监控 API 调用记录、访问量、成功率等等),就必须依赖于另一个日志数据库(需用户自行搭建),来存储 API 访问日志,推荐使用 clickhouse,当然您也可以使用其它的关系型数据库。
目前提供了 clickhouse/mysql 的日志数据库初始化脚本,在
sql目录下
# 日志采集方式
文件采集:DBAPI 默认会将 API 访问日志写入磁盘文件
logs/dbapi-access.log,用户可以自行使用dataxflume等工具采集日志到日志数据库。直连数据库:如果在
conf/application.properties文件配置了access.log.writer=db,那么 DBAPI 会将 API 访问日志直接写入日志数据库,这种方式适用于日志量不太大的场景下。Kafka 缓冲:如果在
conf/application.properties文件配置了access.log.writer=kafka,那么 DBAPI 会将 API 访问日志写入 kafka,用户需要自行从 kafka 采集日志到日志数据库,这种方式适用于日志量大的场景,可以由 kafka 去做数据缓冲。注意此种方式下需要在
conf/application.properties文件填写 kafka 地址。同时 DBAPI 也自带了消费 kafka 日志并写入日志数据库的工具,请使用
bin/dbapi-log-kafka2db.sh脚本。
如果您不需要使用监控功能,可以不用搭建日志数据库,并配置
access.log.writer=null即可。(默认配置就是access.log.writer=null)
# 监控汇总
点击监控菜单可以查看 API 调用记录的监控
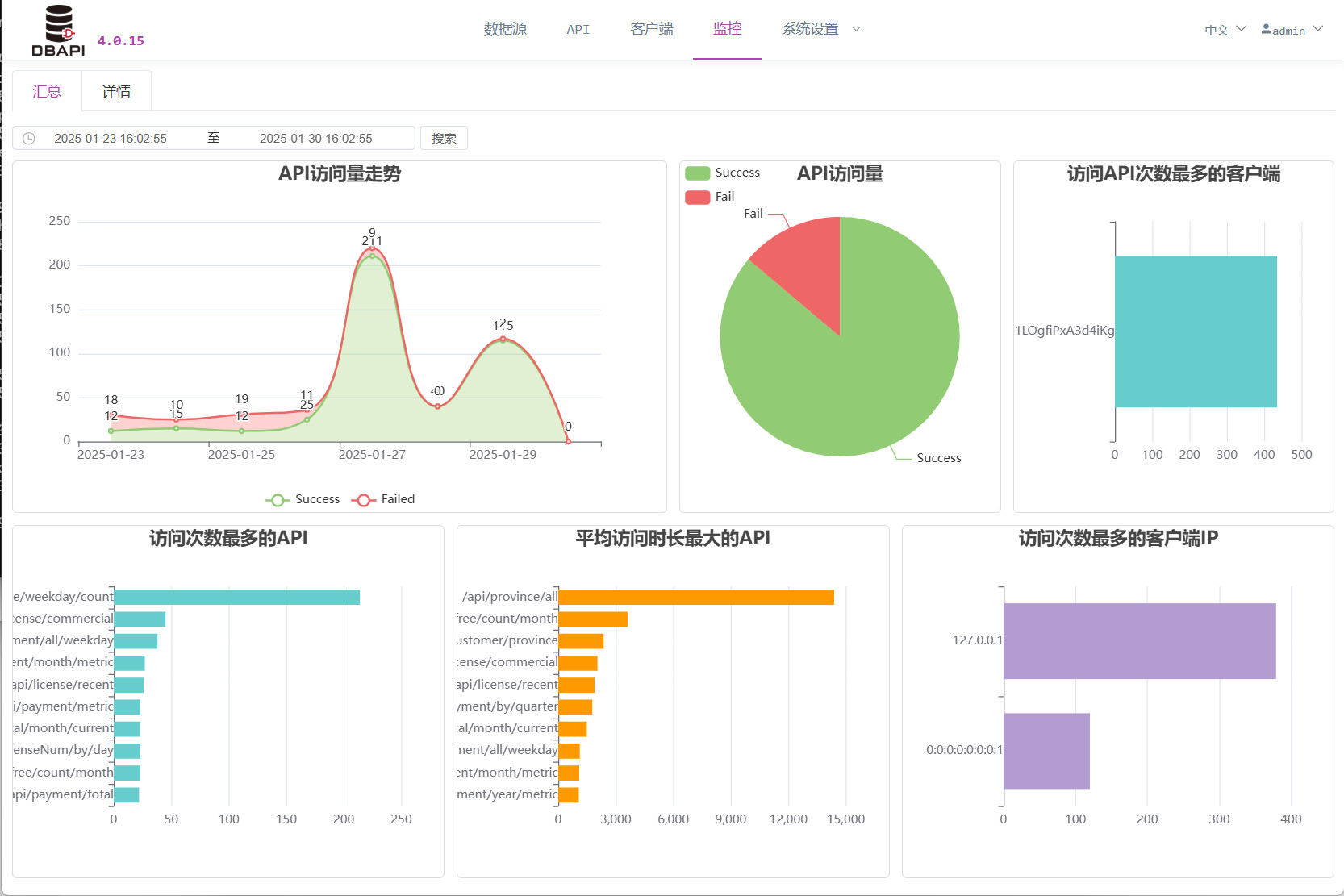
# 查看接口调用记录
点击详情标签,可以搜索 API 调用记录

# 其他功能
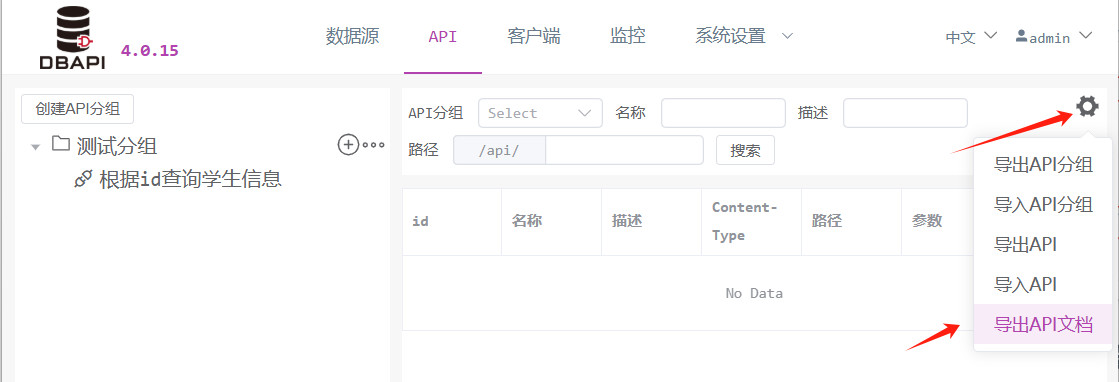
# 导出接口文档
在 API 菜单点击工具按钮,再点击导出接口文档按钮
# 插件体系
DBAPI 提供五类插件机制,您可以在插件市场 (opens new window)下载插件。
# 缓存插件
- 对执行器结果进行缓存,比如 SQL 执行器,对查询类 SQL,SQL 查询结果进行缓存,这样避免频繁的查询数据库,对数据库造成压力。
- 缓存逻辑由用户自己编写,用户可以缓存到 ehcache/redis/mongodb 等等。
- 当从缓存中查询不到数据时,才去执行执行器,同时将结果缓存下来。
SQL 执行器多 SQL 场景:如果是 SQL 执行器,如果一个执行器内包含多条 SQL,那么缓存插件是对多条 SQL 执行的结果(如果单条 SQL 配置了转换插件,会先转换结果)封装成一个整体后,对整体进行缓存
# 告警插件
- 当 API 内部报错的时候,告警插件可以将报错信息发送告警提醒,比如发邮件、短信、钉钉、飞书、企业微信等
- 告警逻辑由用户自己编写
# 数据转换插件
- 有时候 SQL 无法一次性获得自己想要的数据格式,如果用代码对数据进行一些处理转换能更加方便,这时候就要用到数据转换插件。用户自己编写数据转换逻辑的代码。
- 比如针对 SQL 查询结果中的用户手机号、银行卡号进行转换脱敏。
SQL 执行器多 SQL 场景:如果是 SQL 执行器,如果一个执行器内包含多条 SQL,那么每条 SQL 会对应一个数据转换插件配置,数据转换插件永远是针对单条 SQL 查询结果进行转换
# 全局数据转换插件
- API 返回的数据格式默认是
{success: true, msg: xxx, data: xxx} - 有些情况下需要对 response 数据格式进行一些转换,比如前端低代码框架
AMIS就要求接口返回数据必须携带status字段,这个时候就可以用全局数据转换插件对整个 API 的返回数据进行格式转换
插件区别说明:注意数据转换插件和全局数据转换插件的区别,数据转换插件是对执行器执行结果进行格式转换(比如对 SQL 执行器执行查询 SQL 得到的结果进行转换),而全局数据转换插件是对整个 API 执行结果进行格式转换
# 参数处理插件
- 对请求参数进行用户自定义的处理
- 比如将请求参数的值全部转换大写
- 比如 API 接收加密的参数,用户自定义逻辑对参数值进行解密
版本支持说明:注意参数处理插件在个人版
4.0.16、企业版4.1.10版本开始支持
# 注意事项
# 数据源支持
- 如果您要使用 Oracle 或者其他类型的数据源,请将相应的 jdbc 驱动包手动放入 DBAPI 部署后的
extlib目录或者lib目录下(如果是集群部署每个节点都需要手动放入 jar 包) - 推荐放在
extlib目录下,方便统一管理
# SQL 编写规范
- 和 mybatis 动态 SQL 语法一样,同样支持参数
#{}、${},可以参考动态 SQL 语法文档,不需要写最外层的<select><update>等标签,直接写 SQL 内容 - 注意和 mybatis 一样,SQL 里的小于号不要写成
<,要写成<
# 权限校验流程